
- SQL
- 맛집
- 전주
- 도쿄
- 건담
- 시청
- 사진
- ai_엔지니어링
- 해리포터
- 오사카
- 우리fisa
- 17-55
- 우리에프아이에스
- 대만여행
- 제주도
- 전시
- 글로벌소프트웨어캠퍼스
- 축복이
- fdr-x3000
- 우리fis아카데미
- 축복렌즈
- 여행
- k-디지털트레이닝
- Python
- 카페
- 대만
- 수요미식회
- CS231n
- 군산
- 650d
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- Today
- Total
브렌쏭의 Veritas_Garage
스크랩 / 크롤링 본문
스크랩은 웹페이지를 잡지 스크랩하듯이 복사해서 뜯어고치고 붙이는 것, 크롤링은 그 스크래핑을 많이 하거나 자동화하거나.

티스토리에서 블로그를 하다보면, 가끔 이런 메세지가 메일로 날아온다. 물론 구글 애널리틱스를 쓸때 이야기다.
"색인 생성 범위 문제가 일부 해결되지 않았습니다."
또는 이런 문구도 있다.
"색인이 생성되었으나 robots.txt에 의해 차단됨"
막상 내부에 상세보기를 보면, 문제점이 뭔지 알수 있고, 혹은 그냥 저 문장을 구글링하면 답이 나온다. 참고로 들어가보면 다음과 비슷하게 나올 것이다.
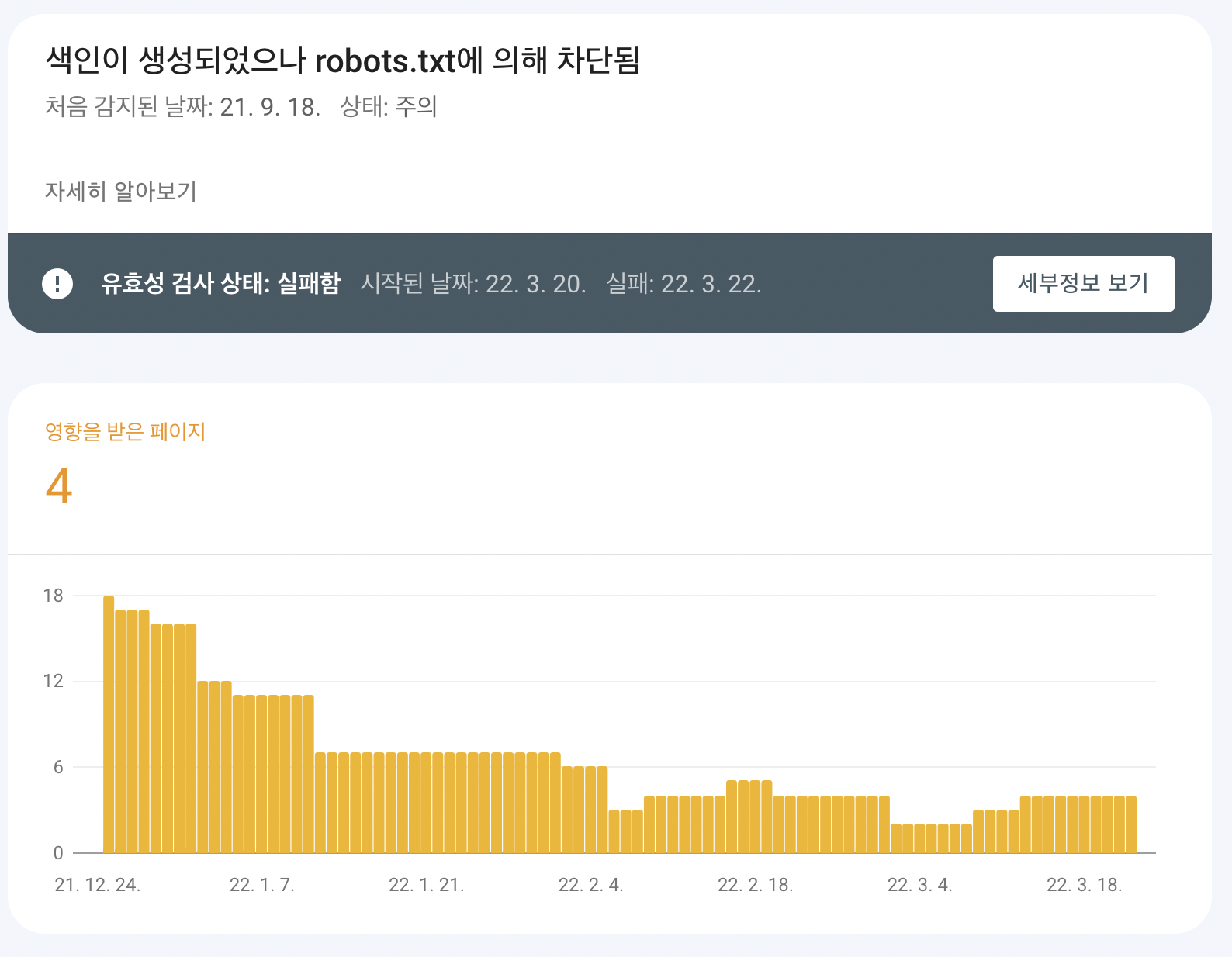
페이지에 대한 색인, Index를 만들었더니 로봇이 구글을 차단먹였다고 하고 있다. 이때 색인을 하는것이 구글의 크롤링 봇이다.
네이버도 비슷한게 있고, 모든 검색엔진은 그런게 있다. 그런걸 주기적으로 써서 전 세계의 웹을 검색 가능하도록 키워드를 수집하고 있는 것이다.
robot.txt
구글도 막아주는 기가 막힌 존재다.
미러, 미러링
혹은 인터넷이 너어무 느려서, 혹은 주로 가는 사이트의 서버가 구데기라서, 아니면 그냥 탐나서 통으로 가져온다면 미러링이라고 한다. 예에에에에전에 엔하위키 미러나 리그베다 위키 미러, 요즘은 무나위키가 그런 미러링 사이트다. 대개 ~~ 미러 라고 부른다.
요즘엔 없지만 인기검색어나 실시간 베스트 글, 이런것도 크롤링을 통해서 나온다. 자신의 사이트든 남의 사이트든 주기적으로 내용을 긁어서 원하는 모양으로 주물럭 거리고, 정리하면 그렇게 보이는 거다.
하이퍼링크 미리보기
요즘에는 어딘가의 하이퍼링크를 달면 자동으로 파비콘이나 미리보기 사진, 거기에 글 제목과 간략한 내용까지 예쁘게 박아주는 것이 기본이다. 이럴때는 원하는 링크의 html 헤드를 보고, 필요한 정보를 취사선택한다. 제목이라면 <h1>헤더에 있을거고.
저작권
모든, 대부분의 저작권이 그렇듯이 개인이 수동으로 몇개 소장하기 위함이면 문제가 크게 없다. 그것을 통해 이제 이익을 취하거나 뿌리거나 하면 문제가 된다. 혹은 무차별적으로 긁어대서 서버에 엿을 먹이거나... 그러니까 세상의 종말을 대비해서 생존주의 사이트들을 다운받아 소장해두길 권한다.
물론 그걸 열람하려면 전기가 있어야겠지
그러므로 최강의 크롤링은 손수 받은 HTML의 출력본 되시겠다. 종이가 짱이다.
OpenGraph
페이스북이 주도한 양식. 헤드 부분에 메타 태그를 적극 활용하여 좀 웹페이지 내용을 미리 써두자. 하고 제안한 것.
메타는 참 웹에 있어서 한 일이 많은데 눈물만 나누나..
헤드를 잘 보면, <meta property="og:이름" content="내용"> 으로 이루어진 곳이 있다. 오픈 그래프는 저 og로 시작하는 프로퍼티를 싸악 가져오는 것이다. 논문 초록같은 것.. 웹을 만들때 지정해두지 않는다면 당연히 못가져온다.
Tools : Cheerio & Puppeteer
스크래핑을 한다면 보통 치리오를, 크롤링을 한다면 퍼페티어를 쓰는 편이다. 퍼페티어는 치리오와 함께 사용도 한다.
cheerio
cheerio Fast, flexible & lean implementation of core jQuery designed specifically for the server. 中文文档 (Chinese Readme) const cheerio = require('cheerio');const $ = cheerio.load(' Hello world ');$('h2.title').text('Hello there!');$('h2').addClass('
cheerio.js.org
지금 위에 뜨는 미리 보기 정보도 og정보인가? 하고 보니 아니었다. 치리오는 상남자라서 홈페이지에 오픈그래프 따위 넣지않아!

https://github.com/puppeteer/puppeteer#readme
GitHub - puppeteer/puppeteer: Headless Chrome Node.js API
Headless Chrome Node.js API. Contribute to puppeteer/puppeteer development by creating an account on GitHub.
github.com
퍼페티어의 경우에는 깃헙에 들어있어서 그런지 빼곡하게 채워져 있더라.
로고도 귀여운게 맘에 든다. 둘러보니 property="fb: 같은 것도 있고 종류가 상당하다. 들어보니 트위터에서도 밀고있는 프로퍼티가 있다고 한다.
작업 흐름
플로우는 대략
- 백엔드 단에서 http:// 나 https://로 시작하는 주소를 찾아낸다
- 해당 사이트를 axios 겟 으로 스크래핑한다
- 그 헤드에서 og: 프로퍼티를 찾는다
- 각각 쓸 값들을 추려서 골라낸다
- 제목, 내용, og들을 모두 db에 저장을 한다
티스토리의 백엔드 개발자들이 저렇게 og가 없는 치리오라도 얼추 괜찮게 나오도록 작업을 해둔것이다...
'[Project_하다] > [Project_공부]' 카테고리의 다른 글
| Optional Chaining (0) | 2022.03.28 |
|---|---|
| Nest.js 를 위한 기초쌓기 #20220328 (0) | 2022.03.28 |
| 파이프라인 or ERD (0) | 2022.03.28 |
| Docker (0) | 2022.03.23 |
| 프로젝트와 package.json (0) | 2022.03.23 |
| Husky..husky...허스키.. & Git hook (0) | 2022.03.23 |
| ESlint & Prettier : 코드의 퀄리티와 스타일 (0) | 2022.03.22 |


