
- 우리fis아카데미
- 17-55
- 해리포터
- 오사카
- 축복렌즈
- 우리fisa
- 글로벌소프트웨어캠퍼스
- 여행
- fdr-x3000
- 우리에프아이에스
- 건담
- 전주
- 도쿄
- CS231n
- 대만
- SQL
- 시청
- k-디지털트레이닝
- 사진
- 전시
- 축복이
- 대만여행
- ai_엔지니어링
- 제주도
- Python
- 650d
- 수요미식회
- 맛집
- 카페
- 군산
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Today
- Total
브렌쏭의 Veritas_Garage
[3Blue1Brown] Generative Pre-trained Transformer 본문
GPT, what is it? -> Transformer
중요한 것은 Transformer라는 용어이다.
맥락과 단서를 제공하면 그에 걸맞는 다음 내용을 예측하고 가장 '어울릴 것이라 생각하는 것'을 도출한다.
굉장히 단순하게 말하자면 네이버나 구글과 같은 검색엔진의 "검색어 자동완성"을 생각해보자

위 예시의 경우에서, 순서대로 가장 높은 예측도라고 가정해보자.
- san 을 집어넣으면 francisco가 뒤에 올것이라 예측한다.
- 그럼 이제 san francisco를 넣고 다시 예측을 시킨다.
- 그러면 이제 san francisco 뒤에 weather라는 글자를 예측할것이다.
- 그럼 다시 san francisco weather까지 적어서 다시 예측을 시킨다.
- 그럼 이제 san francisco weather is 라는 답을 내고
- ....
- ???
PROFIT!!!- "san francisco weather is good in april?" 이라는 문장을 생성하게 된다는 것이다.
정말 이딴 게 Open AI 가 제공하는 Chat GPT의 본질인가? 하고 묻는다면, 어마어마한 학습량과 데이터, 그리고 어떤 방향의 답변을 해야할지 단서를 추가 제공함으로써 그렇게 된다고 할 수 있겠다.
실제로 gpt에 질문을 해보면 한단어 한단어씩 생성되고 로딩이 되는 것을 볼 수 있다.
물론 굉장히 개략적이고 러프한 접근법이지만, 어쨌든 세부 기술을 이해하기 위해서 큰 그림을 알아두었다고 치자.
Token
입력받은 데이터는, 그것이 문장이거나, 이미지이거나, 음성데이터라던가 무엇이든지간에, 일단 작게 쪼개지게 된다.
일단은 텍스트처리라고 생각하고 쭉 이어가 보자.

입력된 텍스트는 작은 덩어리로 나뉘고 각 덩어리는 벡터로 변환되게 된다.
Embedding Matrix
트랜스포머 모델 내부에 미리 내재되어있는 기본 토큰 리스트들이다. 모든 토큰들은 역시나 벡터 형식으로 저장되어있다.
입력된 데이터가 Embedding Matrix를 통과하면서 각각 지정된 벡터로 변경되게 된다.
Word Embeddings
GPT-3 기준으로 각 Word는 만이천개가 넘는 차원을 가지고 있다. 다르게 말하자면 한 단어당 만 이천개 이상의 속성과 특징들이 저장되어 있다고 생각할 수 있다.
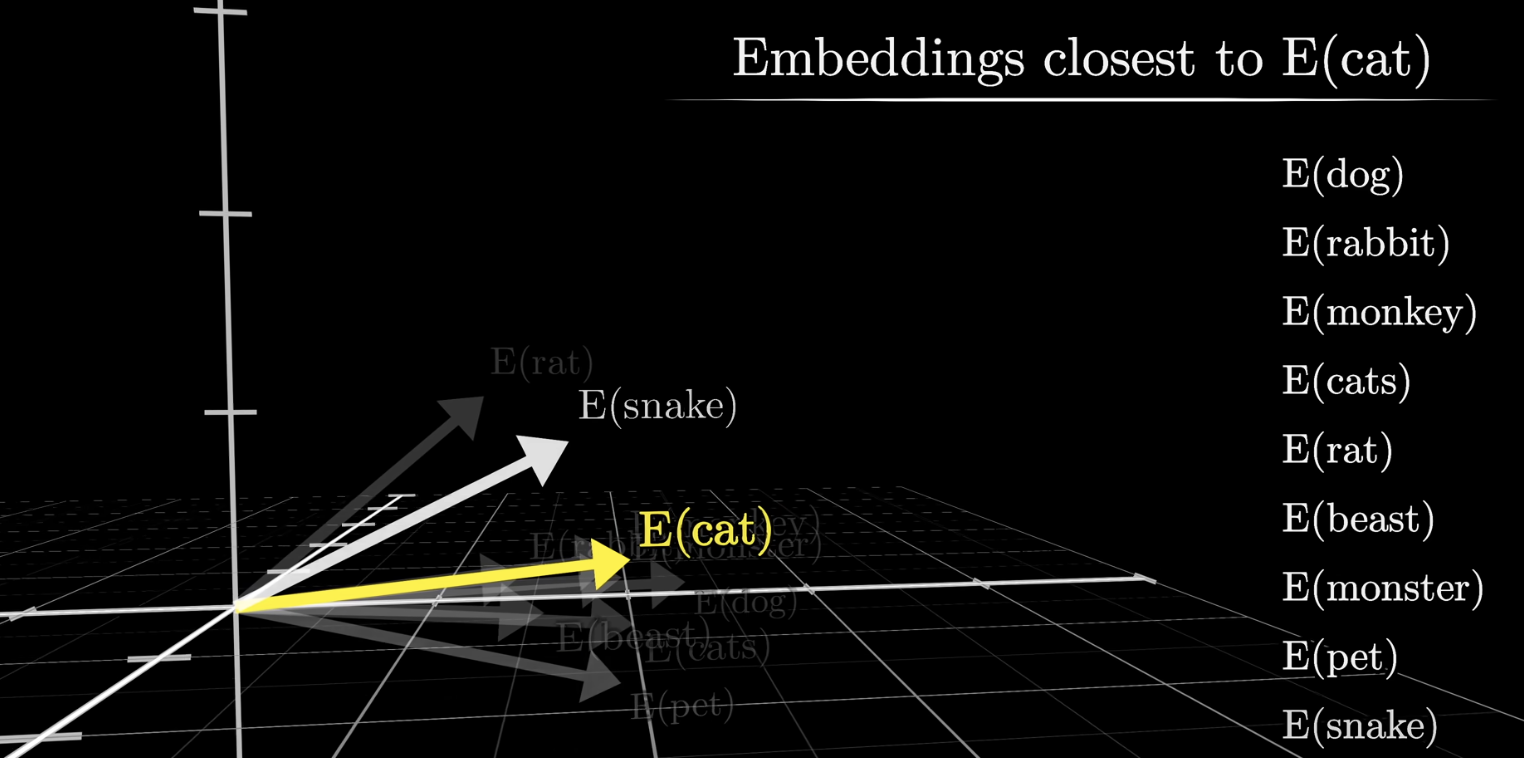
이런 속성들은 임의로 지정하는 것이 아니라, 학습과정에서 모델이 스스로 연관성과 속성을 분류해서 적절한 벡터에 위치시킴으로써 결정된다.
두 벡터의 도트곱은 그 벡터들이 얼마나 잘 정렬되어있는지 판단하는 근거로 사용할 수 있다.
Vocabulary Size
Embedding Matrix에 사전 정의된 토큰의 개수와 각 토큰이 가지고 있는 속성들의 임베딩 차원을 곱하면 모델이 가진 토큰 어휘의 크기를 알 수 있다.

Context
주어진 단어 토큰은 단순히 사전적 정의로 결정되는 것이 아니라, 모든 데이터를 취합하여 문맥 상의 뜻을 통째로 저장하게 된다.
각 단어들이 문맥 상의 뜻을 모두 가지고 있음으로써 이후에 나올 답변에서 나올만한 출력 단어를 예측할 수 있는 단서로 활용된다.
단순히 첫 Embedding Matrix와 매칭될 때에는 기존에 학습된 의미들이 벡터에 지정되지만, 이후 반복적으로 Transformer의 Attention레이어, Multilayer Perceptron을 통과하며 앞뒤 단어들의 연관성과 문맥이 업데이트되게 된다.
이때 한번에 처리할 수 있는 양을 Context Size 라고 하며, 이를 넘어서게 되면 흔히 GPT에서 볼 수 있는, 이전 대화의 맥락을 잊어버린 듯한 답변을 하게 된다.
Unembedding Matrix
최초에 토큰에 Embedding Matrix를 곱해 변환한 것 처럼, 과정의 마지막에서 Unembedding Matrix를 곱해 벡터의 산출 값을 나타내게 한다.
Probablility Distribution
이전 문장을 바탕으로 다음에 올 단어를 예측한다는 것은, 가능성이 높은 후보 단어들이 있고 그 확률에 따라 가장 높은 확률의 단어를 선택하는 것이라는 뜻이다.
즉, 후보군들의 확률은 100% 사이에서, 그 모든 확률의 합이 100%로 나타나야 한다.
Context의 마지막 벡터 값을 바탕으로 다음에 올 가능성이 높은 글자들을 정규분포로 변환해야 하는 것이다.
Softmax
임의의 숫자 목록을 합이 1이되는 정규분포로 변환하는 방법이다.
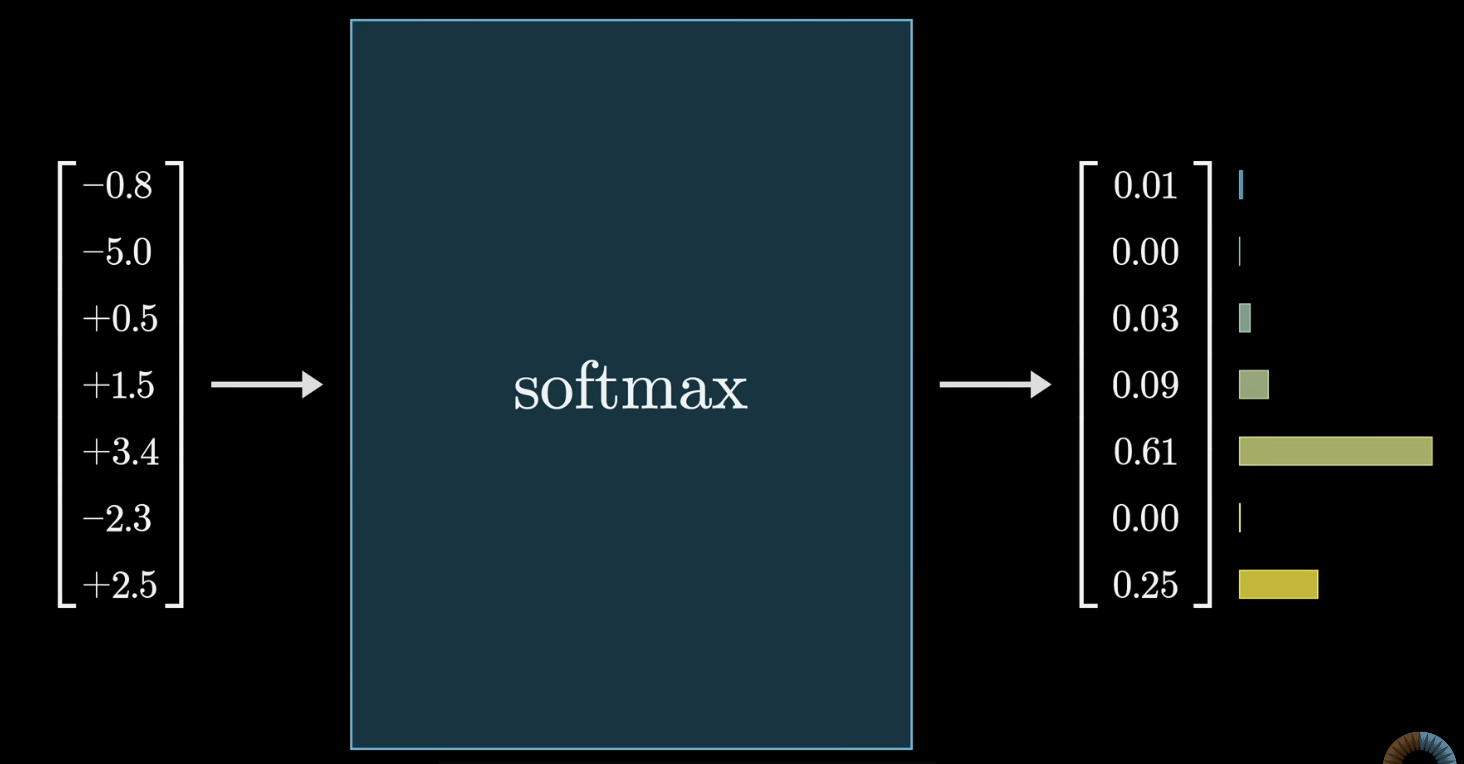
Temp
Softmax를 사용할 때, 얼마나 분포 내부의 값들 간의 차이를 강조할 것인지를 결정한다.
- t 가 높을 수록 확률이 낮은 값에 더 많은 가중치를 줘서 분포가 전반적으로 균등하게 변한다.
- 반대로 t 가 낮을 경우 높은 값에 가중치를 줘 분포간의 차이가 극명하게 드러난다.
0에 가까우면 극단적으로 차이가 드러나는 형태가 되고, 1일때는 t가 없는 것과 동일, 그보다 클수록 낮은 확률을 균등하게 올려 새롭거나 확실하지 않은 대답을 선택할 가능성을 높이게 된다.
'[Project_하다] > [Project_공부]' 카테고리의 다른 글
| [혼공컴운] CS기초, 입문 (0) | 2024.07.06 |
|---|---|
| [BoostCourse] 확률론 (0) | 2024.07.05 |
| [3Blue1Brown] Attention (1) | 2024.07.05 |
| [3Blue1Brown] Backpropagation 역전파 (0) | 2024.07.04 |
| [3Blue1Brown] DeepLearning (1) | 2024.07.01 |
| [CS231n] #4. Neural Network (1) | 2024.07.01 |
| [CS231n] #3. Loss Function, 최적화 (0) | 2024.06.28 |



