
Tags
- 대만
- 우리fisa
- 17-55
- 맛집
- Python
- 해리포터
- 카페
- SQL
- 군산
- CS231n
- 전시
- 글로벌소프트웨어캠퍼스
- 수요미식회
- 대만여행
- 시청
- 도쿄
- 축복이
- 축복렌즈
- 제주도
- 우리fis아카데미
- 650d
- ai_엔지니어링
- 오사카
- 우리에프아이에스
- 여행
- 전주
- 사진
- k-디지털트레이닝
- 건담
- fdr-x3000
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Today
- Total
Recent Posts
300x250
브렌쏭의 Veritas_Garage
[우리FISA] 4일차 RegExp 본문
RegExp
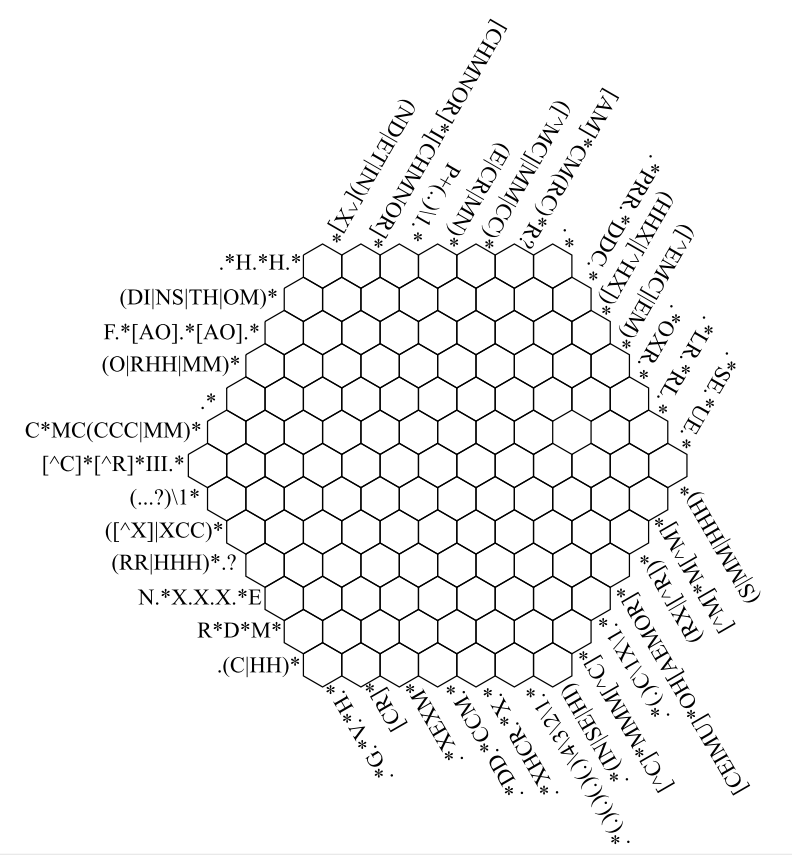
1. 정규표현식
- 문자열을 처리하는 방법 중 하나로, 특정한 규칙을 가진 문자열을 표현하는 데 사용한다.
1.1. 정규표현식의 기본 문법
- 정규표현식은 문자열을 처리하는 방법 중 하나로, 특정한 규칙을 가진 문자열을 표현하는 데 사용한다.
1.1.1. 문자 클래스
- 문자 클래스는 문자열을 표현하는 방법 중 하나로, 대괄호([]) 안에 문자들을 나열하여 표현한다.
- 대괄호 안에 나열된 문자들 중 하나와 일치하는 문자를 찾는다.
import re
# [abc] : a, b, c 중 하나와 일치하는 문자를 찾는다.
print(re.search(r'[abc]', 'apple')) # <re.Match object; span=(0, 1), match='a'>
print(re.search(r'[abc]', 'banana')) # <re.Match object; span=(1, 2), match='a'>
# [a-z] : a부터 z까지 중 하나와 일치하는 문자를 찾는다.
print(re.search(r'[a-z]', 'Apple')) # <re.Match object; span=(1, 2), match='p'>
# [A-Z] : A부터 Z까지 중 하나와 일치하는 문자를 찾는다.
print(re.search(r'[A-Z]', 'apple')) # None
# [0-9] : 0부터 9까지 중 하나와 일치하는 문자를 찾는다.
print(re.search(r'[0-9]', 'apple123')) # <re.Match object; span=(5, 6), match='1'>1.1.2. 메타문자
- 메타문자는 문자열을 표현하는 방법 중 하나로, 특별한 의미를 가진 문자이다.
- 메타문자는 역슬래시()로 시작한다.
import re
# \d : 숫자와 일치하는 문자를 찾는다.
print(re.search(r'\d', 'apple123')) # <re.Match object; span=(5, 6), match='1'>
# \D : 숫자가 아닌 문자를 찾는다.
print(re.search(r'\D', 'apple123')) # <re.Match object; span=(0, 1), match='a'>
# \s : 공백 문자를 찾는다.
print(re.search(r'\s', 'apple 123')) # <re.Match object; span=(5, 6), match=' '>
# \S : 공백이 아닌 문자를 찾는다.
print(re.search(r'\S', 'apple 123')) # <re.Match object; span=(0, 1), match='a'>
# \w : 문자와 숫자를 찾는다.
print(re.search(r'\w', 'apple123')) # <re.Match object; span=(0, 1), match='a'>
# \W : 문자와 숫자가 아닌 문자를 찾는다.
print(re.search(r'\W', 'apple123')) # None1.1.3. 반복패턴
- 반복패턴은 문자열을 표현하는 방법 중 하나로, 특정한 규칙을 가진 문자열을 표현하는 데 사용한다.
- 반복패턴은 중괄호({}) 안에 숫자를 나열하여 표현한다.
import re
# {3} : 3번 반복되는 문자를 찾는다.
print(re.search(r'a{3}', 'aaapple')) # <re.Match object; span=(2, 5), match='aaa'>
# {2, 4} : 2번 이상 4번 이하 반복되는 문자를 찾는다.
print(re.search(r'a{2,4}', 'aaapple')) # <re.Match object; span=(0, 2), match='aa'>1.1.4. 기타
^: 문자열의 시작과 일치하는 문자를 찾는다.$: 문자열의 끝과 일치하는 문자를 찾는다..: 줄바꿈 문자를 제외한 모든 문자와 일치하는 문자를 찾는다.
import re
# ^ : 문자열의 시작과 일치하는 문자를 찾는다.
print(re.search(r'^apple', 'apple')) # <re.Match object; span=(0, 5), match='apple'>
print(re.search(r'^apple', 'banana apple')) # None
# $ : 문자열의 끝과 일치하는 문자를 찾는다.
print(re.search(r'apple$', 'apple')) # <re.Match object; span=(0, 5), match='apple'>
# . : 줄바꿈 문자를 제외한 모든 문자와 일치하는 문자를 찾는다.
print(re.search(r'a.e', 'apple')) # <re.Match object; span=(0, 3), match='app'>1.2. 정규표현식의 함수
- 정규표현식은
re모듈을 사용하여 처리한다. re모듈은 다음과 같은 함수를 제공한다.re.search(패턴, 문자열): 문자열에서 패턴과 일치하는 문자열을 찾는다.re.match(패턴, 문자열): 문자열의 시작부터 패턴과 일치하는 문자열을 찾는다.re.findall(패턴, 문자열): 문자열에서 패턴과 일치하는 문자열을 모두 찾아 리스트로 반환한다.re.finditer(패턴, 문자열): 문자열에서 패턴과 일치하는 문자열을 모두 찾아Match객체로 반환한다.
import re
# re.search(패턴, 문자열): 문자열에서 패턴과 일치하는 문자열을 찾는다.
print(re.search(r'[abc]', 'apple')) # <re.Match object; span=(0, 1), match='a'>
# re.match(패턴, 문자열): 문자열의 시작부터 패턴과 일치하는 문자열을 찾는다.
print(re.match(r'[abc]', 'apple')) # <re.Match object; span=(0, 1), match='a'>
# re.findall(패턴, 문자열): 문자열에서 패턴과 일치하는 문자열을 모두 찾아 리스트로 반환한다.
print(re.findall(r'[abc]', 'apple')) # ['a', 'a']
# re.finditer(패턴, 문자열): 문자열에서 패턴과 일치하는 문자열을 모두 찾아 `Match` 객체로 반환한다.
print(re.finditer(r'[abc]', 'apple')) # <callable_iterator object at 0x7f8b1c3b3d30>
1.3. 정규표현식의 플래그
- 정규표현식은 플래그를 사용하여 처리한다.
- 플래그는 정규표현식의 처리 방법을 지정하는 역할을 한다.
- 플래그는
re모듈의 함수에 인자로 전달하여 사용한다.
import re
# re.IGNORECASE 또는 re.I : 대소문자를 구분하지 않는다.
print(re.search(r'apple', 'Apple', re.IGNORECASE)) # <re.Match object; span=(0, 5), match='Apple'>
# re.MULTILINE 또는 re.M : 여러 줄과 일치한다.
print(re.search(r'^apple', 'apple\nbanana', re.MULTILINE)) # <re.Match object; span=(0, 5), match='apple'>
# re.DOTALL 또는 re.S : 줄바꿈 문자를 포함하여 모든 문자와 일치한다.
print(re.search(r'a.e', 'apple\nbanana', re.DOTALL)) # <re.Match object; span=(0, 3), match='app'>1.4. 정규표현식의 그룹
- 정규표현식은 그룹을 사용하여 처리한다.
- 그룹은 괄호()로 묶어서 표현한다.
- 그룹은
re모듈의 함수에 인자로 전달하여 사용한다.
import re
# 그룹 사용
# (패턴) : 패턴을 그룹으로 묶는다.
print(re.search(r'(apple)', 'apple')) # <re.Match object; span=(0, 5), match='apple'>
# \번호 : 번호에 해당하는 그룹과 일치하는 문자를 찾는다.
print(re.search(r'(apple)\1', 'appleapple')) # <re.Match object; span=(0, 10), match='appleapple'>1.5. 정규표현식의 대체
- 정규표현식은 대체를 사용하여 처리한다.
- 대체는
re모듈의 함수에 인자로 전달하여 사용한다.
import re
# re.sub(패턴, 대체문자열, 문자열): 문자열에서 패턴과 일치하는 문자열을 대체문자열로 변경한다.
print(re.sub(r'apple', 'banana', 'apple apple')) # banana banana1.6. 정규표현식의 컴파일
- 정규표현식은 컴파일을 사용하여 처리한다.
- 컴파일은
re모듈의 함수에 인자로 전달하여 사용한다.
import re
# re.compile(패턴): 패턴을 컴파일한다.
pattern = re.compile(r'apple')
# 컴파일한 패턴을 사용하여 처리한다.
print(pattern.search('apple')) # <re.Match object; span=(0, 5), match='apple'>1.7. 정규표현식의 예외 처리
- 정규표현식은 예외 처리를 사용하여 처리한다.
- 예외 처리는
re모듈의 함수에 인자로 전달하여 사용한다.
import re
# re.error: 정규표현식 에러를 처리한다.
try:
re.compile(r'*')
except re.error:
print('정규표현식 에러')1.8. 정규표현식의 활용
- 정규표현식은 문자열을 처리하는 방법 중 하나로, 특정한 규칙을 가진 문자열을 표현하는 데 사용한다.
1.8.1. 이메일 주소 찾기
- 이메일 주소를 찾는 정규표현식을 사용하여 처리한다.
import re
# 이메일 주소 찾기
# \w+ : 문자와 숫자가 1개 이상 있는 문자열을 찾는다.
# \. : 점 문자를 찾는다.
# [a-zA-Z] : 알파벳 문자를 찾는다.
# {2,} : 2개 이상 있는 문자열을 찾는다.
pattern = re.compile(r'\w+@\w+\.[a-zA-Z]{2,}')
print(pattern.search('email@email.com')) # <re.Match object; span=(0, 14),
1.8.2. 전화번호 찾기
- 전화번호를 찾는 정규표현식을 사용하여 처리한다.
import re
# 전화번호 찾기
# \d{2,3} : 숫자가 2개 이상 3개 이하 있는 문자열을 찾는다.
# - : 하이픈 문자를 찾는다.
# \d{3,4} : 숫자가 3개 이상 4개 이하 있는 문자열을 찾는다.
# - : 하이픈 문자를 찾는다.
# \d{4} : 숫자가 4개 있는 문자열을 찾는다.
pattern = re.compile(r'\d{2,3}-\d{3,4}-\d{4}')
print(pattern.search('010-1234-5678')) # <re.Match object; span=(0, 13), match='010-1234-5678'>1.8.3. URL 찾기
- URL을 찾는 정규표현식을 사용하여 처리한다.
import re
# URL 찾기
# https? : http 또는 https 문자열을 찾는다.
# :// : :// 문자열을 찾는다.
# \w+ : 문자와 숫자가 1개 이상 있는 문자열을 찾는다.
# \. : 점 문자를 찾는다.
# [a-zA-Z]{2,} : 알파벳 문자가 2개 이상 있는 문자열을 찾는다.
pattern = re.compile(r'https?://\w+\.[a-zA-Z]{2,}')
print(pattern.search('https://www.google.com')) # <re.Match object; span=(0, 21), match='https://www.google.com'>1.8.4. 이름 마스킹
- 이름을 마스킹하는 정규표현식을 사용하여 처리한다.
import re
# 이름 마스킹
# \w : 문자와 숫자를 찾는다.
# (?=) : 긍정형 전방탐색을 사용하여 패턴을 찾는다.
# .{2} : 문자가 2개 있는 문자열을 찾는다.
pattern = re.compile(r'\w(?=.{2})')
print(pattern.sub('*', 'apple')) # a***
'[Project_하다] > [Project_공부]' 카테고리의 다른 글
| [우리FISA] 5일차 Functions continue..... (1) | 2024.07.12 |
|---|---|
| [우리FISA] 4일차 Function (0) | 2024.07.11 |
| [Paper] 2003.11755, A Survey of Deep Learning for Scientific Discovery (1) (0) | 2024.07.11 |
| [우리FISA] 3일차 Python 제어문 (0) | 2024.07.10 |
| [우리FISA] 2일차 Python Methods (0) | 2024.07.10 |
| [우리FISA] 2일차 Python Concepts (0) | 2024.07.09 |
| [CS50] Memory Stack, Heap... by swap (0) | 2024.07.09 |
'[Project_하다]/[Project_공부]' Related Articles
more



Comments