
- 우리fis아카데미
- 여행
- 650d
- 축복이
- 사진
- 전시
- 대만
- fdr-x3000
- 군산
- 전주
- 시청
- 도쿄
- 대만여행
- 축복렌즈
- 제주도
- 수요미식회
- CS231n
- 17-55
- ai_엔지니어링
- 맛집
- SQL
- 우리fisa
- k-디지털트레이닝
- 오사카
- 건담
- 글로벌소프트웨어캠퍼스
- 카페
- 해리포터
- Python
- 우리에프아이에스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Today
- Total
브렌쏭의 Veritas_Garage
[Paper] 2003.11755, A Survey of Deep Learning for Scientific Discovery (1) 본문
[Paper] 2003.11755, A Survey of Deep Learning for Scientific Discovery (1)
브렌쏭 2024. 7. 11. 15:08https://ar5iv.labs.arxiv.org/html/2003.11755
A Survey of Deep Learning for Scientific Discovery
Over the past few years, we have seen fundamental breakthroughs in core problems in machine learning, largely driven by advances in deep neural networks. At the same time, the amount of data collected in a wide array o…
ar5iv.labs.arxiv.org
유명한 논문이라고 한다. 유명의 뜻을 모르나
However, a significant obstacle in beginning to use deep learning is simply knowing where to start.
내 삶이나 앞으로의 커리어에 있어서 딥 러닝을 이용한다면 어떨까, 무엇이 가장 적합할까 등을 생각해보기에 좋을 듯 하다
the survey describes in detail (i) methods to use deep learning with less data (self-supervision, semi-supervised learning, and others) and (ii) techniques for interpretability and representation analysis (for going beyond predictive tasks).
- 보다 적은 양의 데이터로 딥러닝을 사용하는 방법
- 그 결과를 분석하고 향후 예측 과정에서 해석을 하기 위한 기술
두가지에 집중해서 조사를 진행한 것으로, 최신의 논문은 아니더라도 딥러닝의 흐름과 특히 최근 급상승의 계기를 알 수 있을 것이다.
Section 2. High Level Considerations for Deep Learning
높은 레벨에서 본다는건 수준이 높다는게 아니라 전반적이고 거대한 담론에 가까운 시야에서 딥러닝을 훑겠다는 이야기다.
딥러닝을 사용할만한 상황은 크게 3가지로 나뉜다.
Prediction Problems :: 중요한 예측 문제를 해결하는 것
입력 데이터를 예측 출력으로 매핑하는 작업입니다.
예를 들어 입력이 생체검사 이미지일 때, 모델은 입력된 이미지의 생체조직이 암의 징후를 보이는지 여부를 예측해야 한다.
이러한 사례는 모델이 목표 함수를 학습하게 하는 것으로 생각할 수 있다.
제공된 데이터를 토대로 결과가 무엇일지 분류하고 판단한다
- 복잡한 목표 함수: 딥 러닝은 수학적으로 명확한 형태나 논리적 규칙 세트가 없는 복잡한 목표 함수를 학습하는 데 적합하다.
- 기후 모델링과 같은 복잡한 프로세스를 (블랙박스 방식으로) 시뮬레이션하는 데 사용될 수 있다
- 다양한 예측 문제:
- 이미지 분류: 의료 영상에서 암 진단
- 자연어 처리: 텍스트에서 감정 분석
- 시계열 예측: 주식 시장 예측
오예 - 추천 시스템: 사용자 선호도에 기반한 제품 추천
- 모델의 학습 과정: 딥 러닝 모델은 입력 데이터와 해당 라벨(정답)을 사용하여 학습한다. 이 과정에서 모델은 입력과 출력 간의 복잡한 관계를 학습하게 됩니다.
- Raw 데이터와 정답지를 제공해서 중간 과정을 학습시키고 (블랙박스) 그것을 새로운 데이터를 예측하는데 사용한다
From Predictions to Understanding :: 예측에서 이해로
과학적 질문과 머신 러닝 문제의 근본적인 차이점
- 과학적 질문은 기저 메커니즘에 대한 이해를 강조한다는 점 이다.
단순히 정확한 예측을 출력하는 것만으로는 충분하지 않다.
- 데이터를 생성하는 과정이나 데이터의 어떤 속성이 관찰된 예측이나 결과로 이어졌는지에 대해 통찰을 얻고자 한다
해석 가능성 도구
- 특징 중요도: 입력의 어떤 특징이 출력 예측에 가장 중요한지 이해하는 도구.
- SHAP (SHapley Additive exPlanations) 같은 방법은 각 입력 특징이 모델 예측에 기여하는 정도를 수치화한다
- 가시화 기법: 입력 데이터의 특정 부분이 모델 예측에 어떻게 영향을 미치는지 시각적으로 표현.
- 이미지 분류에서 특정 이미지 부분이 예측에 미치는 영향을 보여주는 Grad-CAM (Gradient-weighted Class Activation Mapping) 기법
숨겨진 표현 분석:
- 히든 레이어 분석: 딥 러닝 모델의 히든 레이어에 저장된 표현을 분석하여 데이터의 중요한 속성을 찾는다.
- 뉴럴 네트워크가 입력 데이터를 어떻게 인코딩하고 변환하는지 이해한다
- 특징 공간 시각화: t-SNE (t-Distributed Stochastic Neighbor Embedding)나 UMAP (Uniform Manifold Approximation and Projection) 같은 차원 축소 기법을 사용하여, 히든 레이어의 고차원 표현을 2D 또는 3D 공간에 시각화.
- 데이터의 군집 형성 및 관계를 시각적으로 파악할 수 있다.
Complex Transformations of Input Data :: 데이터 증가와 분석 필요성
다양한 과학 분야에서 생성되는 데이터의 양, 특히 시각 데이터의 양이 급격히 증가하고 있다.
- 형광 현미경 이미지, 공간 시퀀싱 데이터, 실험 동영상 등등...
- 이러한 데이터를 효율적으로 분석하고 자동으로 처리할 수 있는 방법에 대한 필요성이 커지고 있다
- 이미지를 처리하고 분석하는 속도보다 새로운 데이터가 업로드 되는 속도가 압도적으로 빠르다
이미지 세분화 (Segmentation)
- 세포 이미지에서 핵 식별: 딥 뉴럴 네트워크 기반의 세분화 모델을 사용하여 세포 이미지에서 자동으로 핵을 식별
- 형광 현미경 이미지에서 각 세포의 핵을 정확하게 찾아내는 작업을 자동화
- 적용 사례: U-Net과 같은 세분화 모델은 의료 영상에서 병변이나 구조를 식별하는 데 널리 사용
- 형광 현미경 이미지에서 각 세포의 핵을 정확하게 찾아내는 작업을 자동화
자세 추정 (Pose Estimation)
- 신경과학 분석을 위한 행동 라벨링: 동영상에서 실험 동물(예: 쥐)의 행동을 신속하게 라벨링하는 시스템을 구축
- 동영상에서 특정 행동(예: 먹기, 걷기 등)을 자동으로 인식하고 라벨링하여, 행동 데이터를 신속하게 분석할 수 있다.
- 적용 사례: DeepLabCut과 같은 모델은 동물 행동 연구에서 자세 추정에 사용
- 동영상에서 특정 행동(예: 먹기, 걷기 등)을 자동으로 인식하고 라벨링하여, 행동 데이터를 신속하게 분석할 수 있다.
데이터 전처리와 변환
- 딥 러닝 모델은 데이터의 전처리와 변환 작업에서도 강력한 도구가 될 수 있다.
- 데이터의 노이즈를 제거하거나, 해상도를 향상시키는 작업
- 적용 사례: Super-resolution imaging을 통해 저해상도 이미지를 고해상도로 변환
- 데이터의 노이즈를 제거하거나, 해상도를 향상시키는 작업
딥 러닝 워크플로우 개요
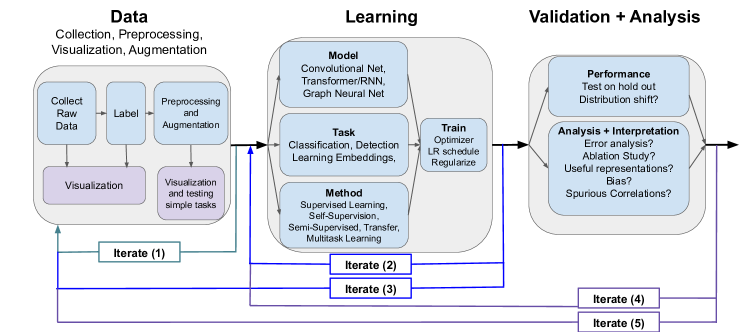
주요 단계와 하위 단계
- 데이터 관련 단계:
- 데이터 수집: 문제 해결에 필요한 데이터를 수집하는 과정
- 다양한 소스에서 데이터를 모으는 작업이 포함
- 데이터 라벨링: 수집된 데이터에 정답 레이블을 부여
- 이 과정에서 데이터의 질을 좌우한다
- 데이터 전처리: 데이터를 분석 가능하게 만들기 위해 전처리 작업을 수행
- 여기에는 결측값 처리, 정규화, 이상치 제거 등이 포함됩니다.
- 데이터 시각화: 데이터를 시각적으로 표현하여 패턴을 이해하고 전처리 및 라벨링 과정의 문제점을 식별합니다.
- 데이터 수집: 문제 해결에 필요한 데이터를 수집하는 과정
- 학습 단계:
- 모델 선택: 해결하려는 문제에 적합한 딥 뉴럴 네트워크 모델을 선택
- 모델의 구조, 레이어 수, 뉴런 수 등을 결정
- 작업 정의: 예측 문제의 종류를 정의합니다.
- 예를 들어, 이미지 분류 작업에서는 입력이 이미지이고 출력은 클래스들의 확률 분포
- 학습 방법: 모델을 학습시키기 위한 방법을 선택
- 지도 학습, 비지도 학습, 강화 학습 등이 있으며, 각 방법은 데이터의 특성과 문제의 요구에 따라 선택
- 모델 선택: 해결하려는 문제에 적합한 딥 뉴럴 네트워크 모델을 선택
- 검증 및 분석 단계:
- 성능 평가: 모델의 성능을 평가하기 위해 테스트 데이터를 사용
- 일반적으로 정확도, 정밀도, 재현율 등의 지표를 사용한다
- 해석 및 분석: 모델의 예측 결과를 분석하고 해석
- 모델이 데이터를 어떻게 이해하고 있는지 파악
- Ablation Study: 모델의 각 구성 요소를 하나씩 제거하거나 변경하면서 성능 변화를 분석
- 모델의 각 부분이 성능에 어떻게 기여하는지 파악
- 성능 평가: 모델의 성능을 평가하기 위해 테스트 데이터를 사용
반복적 과정의 중요성
각 단계는 순차적으로 진행되지만, 실제 개발 과정에서는 여러 번의 반복이 필요하다.
- 첫 번째 시도에서 종종 실패가 발생하기 때문
- 설계 과정의 반복적 특성을 염두에 두고,
- 각 단계의 결과가 다른 단계의 재설계 및 재실행에 영향을 미치는 과정을 고려해야 함
반복적 과정의 예시
- Iterate (1): 데이터 시각화 후 라벨링 과정을 조정.
- 예를 들어, 처음 라벨링 메커니즘이 너무 노이즈가 많거나 목표를 잘 포착하지 못할 경우, 이를 수정
- Iterate (2): 학습 과정에서 다른 작업이나 방법이 더 적합하다고 판단되면 이를 수정
- 예를 들어, 자가 지도 학습 후 지도 학습을 수행하는 등으로 학습 과정을 여러 단계로 나눌 수 있다.
- Iterate (3): 학습 결과에 따라 데이터 관련 단계를 변경
- Iterate (4): 검증 결과에 따라 학습 과정을 다시 설계
- 예를 들어, 모델이 훈련 데이터에 과적합되었다면, 훈련 시간을 줄이거나 더 단순한 모델을 사용
- Iterate (5): 검증 및 분석 결과에 따라 데이터 수집 및 전처리 단계를 개선
- 예를 들어, 모델이 데이터의 잘못된 속성에 의존하고 있음을 발견하면 데이터 수집/정제를 개선
'[Project_하다] > [Project_공부]' 카테고리의 다른 글
| [BoostCouse] NumPy (1) | 2024.07.14 |
|---|---|
| [우리FISA] 5일차 Functions continue..... (1) | 2024.07.12 |
| [우리FISA] 4일차 Function (0) | 2024.07.11 |
| [우리FISA] 4일차 RegExp (0) | 2024.07.11 |
| [우리FISA] 3일차 Python 제어문 (0) | 2024.07.10 |
| [우리FISA] 2일차 Python Methods (0) | 2024.07.10 |
| [우리FISA] 2일차 Python Concepts (0) | 2024.07.09 |


