
Tags
- 건담
- 축복렌즈
- 전시
- 사진
- 우리fisa
- 맛집
- Python
- 전주
- fdr-x3000
- 글로벌소프트웨어캠퍼스
- 군산
- ai_엔지니어링
- 대만
- SQL
- 제주도
- 우리에프아이에스
- 오사카
- 시청
- 카페
- 수요미식회
- 650d
- CS231n
- 대만여행
- k-디지털트레이닝
- 17-55
- 여행
- 축복이
- 우리fis아카데미
- 도쿄
- 해리포터
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Today
- Total
Recent Posts
300x250
브렌쏭의 Veritas_Garage
[우리FISA] NumPy 본문
Numeric + Python = NumPy

NumPy -
Use the interactive shell to try NumPy in the browser
numpy.org
W3Schools.com
W3Schools offers free online tutorials, references and exercises in all the major languages of the web. Covering popular subjects like HTML, CSS, JavaScript, Python, SQL, Java, and many, many more.
www.w3schools.com
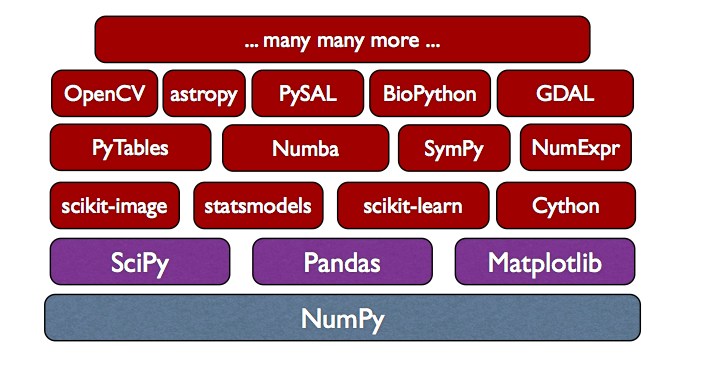
The fundamental package for scientific computing with Python
- 선형대수 관련 수치 연산을 지원하고 내부적으로는 C로 구현되어 있다.
- 데이터 사이언스 분야에서 사용되는 라이브러리들의 토대
- Pandas: Python Data Analysis Library
- Scikit-learn: Machine Learning in Python
- Matplotlib: Python plotting
- SciPy: Scientific Computing Tools for Python
- TensorFlow: An open source machine learning framework for everyone
- PyTorch: Tensors and Dynamic neural networks in Python with strong GPU acceleration
- ...
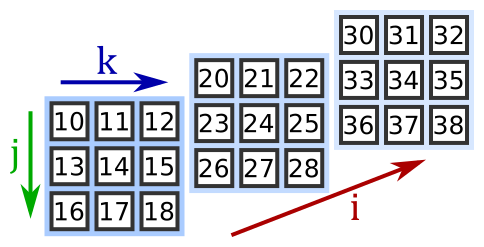
집합자료형의 차원
ndarray
: NumPy만의 차원을 가진 숫자들의 집합 자료형을 위한 클래스(자료형)
- Numpy Dimension Arrray
- Numpy의 핵심인 다차원 행렬 자료구조 클래스
- 동일 타입의 elements
[0, True, {} ] ,[1,2,3]
- 동일 타입의 elements
- 메모리 최적화, 계산 속도 향상
- 벡터화 연산 가능
import numpy as np
# 1차원 배열
a = np.array([1, 2, 3])
print(a) # [1 2 3]
# 2차원 배열
b = np.array([[1, 2, 3], [4, 5, 6]])
print(b)
# [[1 2 3]
# [4 5 6]]
# 3차원 배열
c = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
print(c)
# [[[ 1 2 3]
# [ 4 5 6]]
#
# [[ 7 8 9]
# [10 11 12]]]Python List vs NumPy Array
- Python List
- 다양한 데이터 타입을 담을 수 있다.
- 메모리 사용량이 크다.
- 느리다.
- 벡터화 연산이 불가능하다.
- NumPy Array
- 동일한 데이터 타입을 담을 수 있다.
- 메모리 사용량이 작다.
- 빠르다.
- 벡터화 연산이 가능하다.
import numpy as np
# Python List
a = [1, 2, 3]
b = [4, 5, 6]
# NumPy Array
c = np.array([1, 2, 3])
d = np.array([4, 5, 6])
print(a + b) # [1, 2, 3, 4, 5, 6]
print(c + d) # [5 7 9]ndarray의 속성, 특징
- NumPy에서 제공하는 데이터 타입 중 하나
- 다차원 배열을 효과적으로 처리할 수 있는 라이브러리
import numpy as np
- ndarray.ndim: 배열의 축(차원)의 개수
- ndarray.shape: 배열의 형태
- ndarray.size: 배열의 요소의 총 개수
- ndarray.dtype: 배열 요소의 데이터 타입
- ndarray.itemsize: 배열 요소의 데이터 타입의 크기
- ndarray.data: 실제 배열 요소를 가지고 있는 버퍼
- ndarray.strides: 배열의 요소 사이의 바이트 수
- ndarray.flags: 배열의 속성 정보
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.ndim) # 2
print(a.shape) # (2, 3)
print(a.size) # 6
print(a.dtype) # int64
print(a.itemsize) # 8
print(a.data) # <memory at 0x7f8b1c1b3b80>NumPy Array 생성
- np.array(): 리스트, 튜플, 배열로부터 ndarray를 생성
- np.zeros(): 모든 요소를 0으로 생성
- np.ones(): 모든 요소를 1로 생성
- np.full(): 모든 요소를 지정한 값으로 생성
- np.eye(): 단위 행렬 생성
- np.random.random(): 무작위 값으로 채워진 배열 생성
파이썬 내부 list는 값이 아닌 주소값을 저장하고 있지만, numpy array는 값 자체를 저장하고 있다.
- 바이트 단위로 메모리를 효율적으로 사용할 수 있다.
- 빠른 속도로 데이터를 처리할 수 있다.
Non Destructive Method
- NumPy의 methods들은 원본 데이터를 변경하지 않고 새로운 데이터를 생성하여 반환한다.
- 기본 내장 method들은 원본 데이터를 변경한다.
import numpy as np a = np.array([1, 2, 3, 4, 5])
# Non Destructive Method
b = a.reshape(1, 5)
print(b) # [[1 2 3 4 5]]
# Destructive Method
a.resize(1, 5)
print(a) # [[1 2 3 4 5]]NumPy Array Indexing
- Slicing: 배열의 일부분을 가져오는 방법
- Integer Indexing: 배열의 특정 위치의 값을 가져오는 방법
- Boolean Indexing: 배열의 조건에 따라 값을 가져오는 방법
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# Slicing
print(a[0]) # [1 2 3]
print(a[0, 0]) # 1
print(a[1, 2]) # 6
print(a[1:]) # [[4 5 6] [7 8 9]]
print(a[1:, 1:]) # [[5 6] [8 9]]
print(a[1:, 0]) # [4 7]
# Integer Indexing
print(a[a > 5]) # [6 7 8 9]Data Type of NumPy Array
- int64: 64-bit integer
- uint64: unsigned 64-bit integer
- float64: 64-bit float
- complex: 복소수
- bool: Boolean
- object: Python Object(객체)
- string: String
- unicode: Unicode
import numpy as np
a = np.array([1, 2, 3])
print(a.dtype) # int64
b = np.array([1.0, 2.0, 3.0])
print(b.dtype) # float64
c = np.array([1, 2, 3], dtype=float)
print(c.dtype) # float64
d = np.array([1, 2, 3], dtype=str)
print(d.dtype) # <U1numpy.nan vs numpy.isnan()
- numpy.nan: Not a Number
- 자료형 불일치를 막으면서 데이터를 처리할 수 있도록 해준다.
- 데이터가 없는 경우, 데이터가 잘못된 경우
- None과 같은 역할이나 데이터 타입이 float이다.
- numpy.isnan(): NaN인지 확인하는 함수
inf : infinity
- 무한대를 표현하는 상수
numpy.inf: 양의 무한대-numpy.inf: 음의 무한대
import numpy as np
a = np.array([1, 2, np.nan, np.inf, -np.inf])
print(a) # [ 1. 2. nan inf -inf]
print(np.isnan(a)) # [False False True False False]
print(np.isinf(a)) # [False False False True True]Random
- np.random.seed(): 랜덤 시드 설정
- 같은 랜덤 값을 사용하고 싶을 때 사용
- 동일한 코드셀에서만 동일한 랜덤 값을 사용(Jupyter Notebook)
- np.random.rand(): 0부터 1사이의 균등 분포
- np.random.randn(): 가우시안 표준 정규 분포 (평균 0, 표준편차 1)
- np.random.randint(): 균일 분포의 정수 난수
- np.random.shuffle(): 기존의 데이터의 순서 바꾸기
- np.random.choice(): 기존의 데이터에서 sampling
import numpy as np
np.random.seed(0)
a = np.random.rand()
print(a) # [0.5488135 0.71518937 0.60276338 0.54488318 0.4236548 ]
b = np.random.randn()
print(b) # [ 0.95008842 -0.15135721 -0.10321885 0.4105985 0.14404357]
c = np.random.randint(1, 10)
print(c) # [6 1 4 4 8]
d = np.array([1, 2, 3, 4, 5])
np.random.shuffle(d)
print(d) # [3 2 5 4 1]
e = np.random.choice(d, 3, replace=False)
print(e) # [2 3 5]
Mean, Median, Mode, Average
- Mean: 평균
- 산술 평균
np.mean()
- Median: 중앙값
- 데이터의 중앙에 위치한 값
np.median()
- Average: 가중 평균
- 각 데이터의 가중치를 고려한 평균
np.average()
import numpy as np
a = np.array([1, 2, 3, 4, 5])
print(np.mean(a)) # 3.0
print(np.median(a)) # 3.0
print(np.average(a)) # 3.0Concatenate
- np.concatenate(): 배열을 합치는 함수
axis를 기준으로 합친다.axis=0: 수직으로 합친다.axis=1: 수평으로 합친다.
import numpy as np
a = np.array([[1, 2], [3, 4], [5, 6], [7, 8]])
b = np.array([[9, 10], [11, 12]])
c = np.concatenate((a, b), axis=0)
print(c)
# [[ 1 2]
# [ 3 4]
# [ 5 6]
# [ 7 8]
# [ 9 10]
# [11 12]]
d = np.concatenate((a, b), axis=1)
print(d)
# [[ 1 2 9 10]
# [ 3 4 11 12]
# [ 5 6 0 0]
# [ 7 8 0 0]]Slicing
- np.split(): 배열을 나누는 함수
axis를 기준으로 나눈다.axis=0: 수직으로 나눈다.axis=1: 수평으로 나눈다.
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]])
b, c = np.split(a, [2])
print(b)
# [[1 2 3]
# [4 5 6]]
print(c)
# [[ 7 8 9]
# [10 11 12]]
d, e = np.split(a, [2], axis=1)
print(d)
# [[ 1 2]
# [ 4 5]
# [ 7 8]
# [10 11]]
print(e)
# [[ 3]
# [ 6]
# [ 9]
# [12]]loop ndarray
- np.nditer(): 다차원 배열을 순회하는 함수
order를 기준으로 순회한다.order='C': C-style 순회order='F': Fortran-style 순회
import numpy as np
a = np.array([[1, 2], [3, 4], [5, 6]])
for x in np.nditer(a):
print(x, end=' ') # 1 2 3 4 5 6
for x in np.nditer(a, order='F'):
print(x, end=' ') # 1 3 5 2 4 6Broadcasting
- Broadcasting: 형상이 다른 배열끼리 연산을 수행할 수 있도록 하는 메커니즘
- 두 배열의 형상을 맞추는 방법
- 두 배열의 형상을 맞추는 방법
- 두 배열의 형상을 맞추는 방법
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = np.array([1, 2, 3])
c = a + b
print(c)
# [[ 2 4 6]
# [ 5 7 9]
# [ 8 10 12]]Universal Functions
- Universal Functions: 배열의 각 요소에 대한 연산을 수행하는 함수
np.add(): 덧셈np.subtract(): 뺄셈np.multiply(): 곱셈np.divide(): 나눗셈np.exp(): 지수np.sqrt(): 제곱근np.sin(): 사인np.cos(): 코사인np.tan(): 탄젠트np.log(): 로그
import numpy as np
a = np.array([1, 2, 3, 4, 5])
b = np.add(a, 1)
print(b) # [2 3 4 5 6]
c = np.subtract(a, 1)
print(c) # [0 1 2 3 4]
d = np.multiply(a, 2)
print(d) # [ 2 4 6 8 10]
e = np.divide(a, 2)
print(e) # [0.5 1. 1.5 2. 2.5]
f = np.exp(a)
print(f) # [ 2.71828183 7.3890561 20.08553692 54.59815003 148.4131591 ]
# e^1, e^2, e^3, e^4, e^5
g = np.sqrt(a)
h = np.sin(a)
i = np.cos(a)
j = np.tan(a)
k = np.log(a)Linear Algebra
- np.dot(): 행렬 곱셈
- np.transpose(): 전치 행렬
- np.linalg.inv(): 역행렬
- np.linalg.det(): 행렬식
- np.linalg.eig(): 고유값, 고유벡터
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
c = np.dot(a, b)
print(c)
# [[19 22]
# [43 50]]
'[Project_하다] > [Project_공부]' 카테고리의 다른 글
| [우리FISA] EDA(Exploratory Data Analysis) (0) | 2024.07.19 |
|---|---|
| [@mohsin.shaikh324] Matplotlib vs. Seaborn vs. Plotly (0) | 2024.07.19 |
| [우리FISA] Pandas method and functions (0) | 2024.07.18 |
| [우리FISA] Python Class (0) | 2024.07.16 |
| [우리FISA] OOP (0) | 2024.07.15 |
| [우리FISA] Standard Input/Output, stdio (0) | 2024.07.15 |
| [우리FISA] Exception Handling (0) | 2024.07.15 |
'[Project_하다]/[Project_공부]' Related Articles
more


Comments