
- 대만
- ai_엔지니어링
- 17-55
- 전주
- 도쿄
- SQL
- 군산
- 우리fisa
- 제주도
- 전시
- 건담
- Python
- fdr-x3000
- 카페
- k-디지털트레이닝
- CS231n
- 수요미식회
- 650d
- 우리에프아이에스
- 대만여행
- 여행
- 시청
- 사진
- 오사카
- 우리fis아카데미
- 맛집
- 글로벌소프트웨어캠퍼스
- 축복이
- 해리포터
- 축복렌즈
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Today
- Total
브렌쏭의 Veritas_Garage
[우리FISA] Pandas method and functions 본문
Pandas, Panel Data System

pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool,
built on top of the Python programming language.
- 데이터 분석을 위한 라이브러리
- 데이터를 효과적으로 처리하고, 보여줄 수 있는 다양한 기능을 제공
판다스 10분 완성 / 10 Minutes to Pandas
Pandas 10분 완성 역자 주 : 본 자료는 10 Minutes to Pandas (하단 원문 링크 참조)의 한글 번역 자료로, 번역은 데잇걸즈2 프로그램 교육생 모두가 함께 진행하였습니다. 데잇걸즈2는 과학기술정보통신
dataitgirls2.github.io
Panel Data System?
- 다양한 데이터를 효과적으로 처리할 수 있는 자료구조를 제공
- 여러 개체들을 시간을 두고 추적하여 얻는 데이터
실제로 Panel이라는 자료구조는 pandas에서 제공하지 않는다. (pandas 0.25.0 버전 이후로 제공하지 않음)
- 패널 분석을 위해서는 pandas 를 바탕으로 확장된 라이브러리를 사용하는게 일반적인듯
- xarray? (다차원 배열을 다루는 라이브러리)
- statsmodels? (통계분석 라이브러리)
- ..... etc
패널데이터 == 3차원 데이터: 2차원 데이터프레임이 여러 개 모여있는 것
판다스의 특징
- NumPy를 내부적으로 활용 == NumPy의 특징을 그대로 가진다
- 많은 양의 데이터를 로드해서 분석하는데 최적화
- 데이터분석에 특화된 데이터 구조를 제공
- Series: 1차원 배열
- DataFrame: 2차원 배열
- 다양한 데이터 분석 함수를 제공합니다
pd.read_csv(),pd.to_csv(),pd.read_excel(),pd.to_excel(),pd.read_sql()- .....
한도 끝도 없음
- 다른 시스템에 쉽게 연결가능
- Flask 라이브러리: 웹 개발
- SQL: 데이터베이스
- Sklearn: 머신러닝
보통 시계열 데이터를 다루는데 많이 사용하는 것 같다. (추적조사 등)
판다스의 자료구조
DataFrame
- 2차원 데이터 구조
- 행과 열이 있는 테이블 데이터
DataFrame: 엑셀과 같이, 인덱스(index), 변수(column), 값(value)로 이루어진 데이터 구조. 판다스의 특수한 자료형.
- 복잡한 기능을 구현하기 쉽고, 데이터 전처리를 쉽게 할 수 있다.
- Numpy 라이브러리에서 지원하는 수학 및 통계 연산을 그대로 이용할 수 있다.
- 엑셀 스프레드시트, 데이터베이스등과 동일한 2차원 구조로 가장 구조적인 데이터 형태로써 직관적
- Series가 합쳐진 형태
| Index | Column1 | Column2 | Column3 |
|---|---|---|---|
| Index1 | 1 | 2 | 3 |
| Index2 | 4 | 5 | 6 |
| Index3 | 7 | 8 | 9 |
Index
- 각 행을 식별하는 이름
Column
- 각 열을 식별하는 이름, 변수
Value
- 데이터 값 (숫자, 문자열, 불리언 등)
- 데이터프레임의 값은 서로 다른 데이터 타입을 가질 수 있다.
- 데이터프레임의 값은 데이터프레임의 행과 열에 대한 레이블을 가지고 있다.
Series
- 1차원 데이터 구조
- Dictionary와 비슷한 구조
- Index와 Value로 이루어진 데이터 구조
- DataFrame의 한 열이 Series
- DataFrame의 한 행이 Series
Series: 1차원 데이터 구조. 판다스의 특수한 자료형.
| Index | Value |
|---|---|
| Index1 | 1 |
| Index2 | 2 |
| Index3 | 3 |
Index
- 각 데이터를 식별하는 이름
- 디폴트 인덱스는 0부터 시작하는 정수
- 인덱스를 따로 지정하지 않으면, 디폴트 인덱스가 사용된다.
- 인덱스를 따로 지정할 수 있다.
pd.Series(data, index=[index1, index2, index3])pd.Series(data, index=[index1, index2, index3], name='column_name')
- 인덱스를 통해 데이터에 접근할 수 있다.
series[index]series.loc[index]
Value
- 데이터 값 (숫자, 문자열, 불리언 등)
- 데이터프레임의 값은 서로 다른 데이터 타입을 가질 수 있다.
pd.Series([1, 'a', True])
- 데이터프레임의 값은 서로 다른 데이터 타입을 가질 수 있다.
- 데이터프레임의 값은 데이터프레임의 행과 열에 대한 레이블을 가지고 있다.
pd.Series([1, 2, 3], index=['a', 'b', 'c'], name='column_name')
판다스의 기능
- 데이터 불러오기
pd.read_csv(),pd.read_excel(),pd.read_sql()
- 데이터 저장하기
pd.to_csv(),pd.to_excel()
- 데이터 확인하기
df.head(),df.tail(),df.info(),df.describe()
- 데이터 선택하기
df['column_name'],df[['column_name1', 'column_name2']],df.loc[],df.iloc[]
- 데이터 정렬하기
df.sort_values(),df.sort_index()df.sort_values(by='column_name', ascending=False)df.sort_index(ascending=False)
- 데이터 필터링하기
df['column_name'] > 10df[df['column_name'] > 10]
- 데이터 그룹핑하기
df.groupby('column_name')df.groupby('column_name').mean()
- 데이터 합치기
pd.concat(),pd.merge()
df.loc[] vs df.iloc[]
df.loc[]: 인덱스 이름으로 데이터에 접근df.iloc[]: 인덱스 번호로 데이터에 접근
import pandas as pd
data = {
'name': ['A', 'B', 'C', 'D', 'E'],
'score': [100, 90, 80, 70, 60],
'grade': ['A', 'B', 'C', 'D', 'F']
}
df = pd.DataFrame(data)
# 인덱스 이름으로 데이터에 접근
print(df.loc[0]) # 0번째 행 데이터
print(df.loc[0, 'name']) # 0번째 행의 name 열 데이터
# 인덱스 번호로 데이터에 접근
print(df.iloc[0]) # 0번째 행 데이터
print(df.iloc[0, 0]) # 0번째 행의 0번째 열 데이터df[] vs df.loc[]
df[]: 열 선택df.loc[]: 행 선택
import pandas as pd
data = {
'name': ['A', 'B', 'C', 'D', 'E'],
'score': [100, 90, 80, 70, 60],
'grade': ['A', 'B', 'C', 'D', 'F']
}
df = pd.DataFrame(data)
# 열 선택
print(df['name']) # name 열 데이터
print(df[['name', 'score']]) # name, score 열 데이터
# 행 선택
print(df.loc[0]) # 0번째 행 데이터
print(df.loc[0, 'name']) # 0번째 행의 name 열 데이터concat() vs merge()
concat(): 데이터프레임을 합치는 함수pd.concat([df1, df2])pd.concat([df1, df2], axis=1)
merge(): 데이터프레임을 합치는 함수pd.merge(df1, df2, on='column_name')pd.merge(df1, df2, left_on='column_name1', right_on='column_name2')
import pandas as pd
data1 = {
'name': ['A', 'B', 'C', 'D', 'E'],
'score': [100, 90, 80, 70, 60],
'grade': ['A', 'B', 'C', 'D', 'F']
}
data2 = {
'name': ['F', 'G', 'H', 'I', 'J'],
'score': [50, 40, 30, 20, 10],
'grade': ['F', 'F', 'F', 'F', 'F']
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# 데이터프레임을 합치는 함수
print(pd.concat([df1, df2])) # 행으로 합치기
# print(pd.concat([df1, df2], axis=1)) # 열로 합치기
# 데이터프레임을 합치는 함수
print(pd.merge(df1, df2, on='grade')) # grade 열을 기준으로 합치기
# print(pd.merge(df1, df2, left_on='grade', right_on='grade')) # grade 열을 기준으로 합치기Subset Observations (Rows)
- 데이터프레임의 행을 선택하는 함수
df.loc[]: 인덱스 이름으로 데이터에 접근df.iloc[]: 인덱스 번호로 데이터에 접근
loc[]
- 인덱스 이름으로 데이터에 접근
df.loc[index]: index 행 데이터를 선택df.loc[index, 'column_name']: index 행의 column_name 열 데이터를 선택df.loc[index1:index2]: index1부터 index2까지의 행 데이터를 선택df.loc[index1:index2, 'column_name1':'column_name2']: index1부터 index2까지의 행과 column_name1부터 column_name2까지의 열 데이터를 선택
iloc[]
- 인덱스 번호로 데이터에 접근
df.iloc[index]: index 행 데이터를 선택df.iloc[index, column_index]: index 행의 column_index 열 데이터를 선택df.iloc[index1:index2]: index1부터 index2까지의 행 데이터를 선택df.iloc[index1:index2, column_index1:column_index2]: index1부터 index2까지의 행과 column_index1부터 column_index2까지의 열 데이터를 선택
JOIN
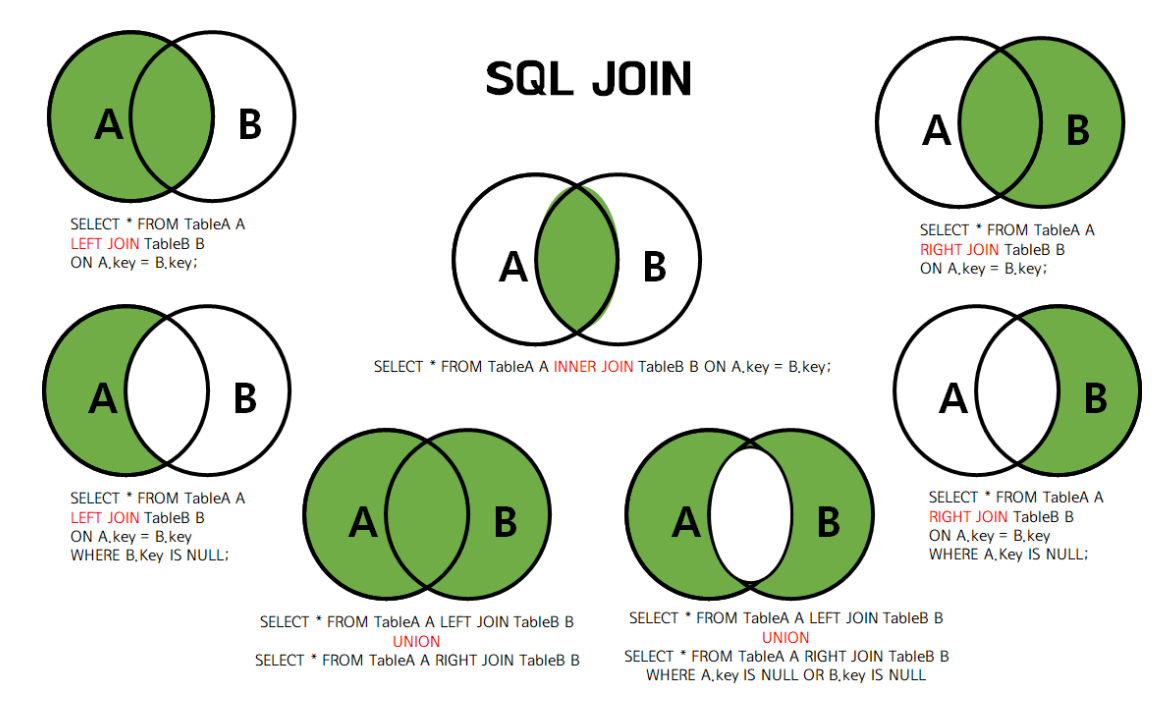
- 기본적으로 SQL의 JOIN과 동일한 기능을 제공한다.
- INNER JOIN: 두 데이터프레임의 공통된 열을 기준으로 데이터를 합친다.
- OUTER JOIN: 두 데이터프레임의 모든 열을 기준으로 데이터를 합친다.
- LEFT JOIN: 왼쪽 데이터프레임의 모든 열을 기준으로 데이터를 합친다.
- RIGHT JOIN: 오른쪽 데이터프레임의 모든 열을 기준으로 데이터를 합친다.
판다스는 컬럼(열) 벡터가 기본이다.
- ndarray[행][열]
- DataFrame[열][행]
【python】pandasのDataFrameを結合(merge, join, concat)する方法 | プログラミングLab
この記事ではpandasライブラリにおけるDataFrameを結合(merge, join, concat)する方法を具体的に解説します。 サンプルコードをコピペしながらサクサク処理を試せますので、 ぜひ活用してみてくだ
junpage.com
INNER JOIN
- 두 데이터프레임의 공통된 열을 기준으로 데이터를 합친다.
- 공통된 열이 없는 경우, 데이터가 합쳐지지 않는다.
OUTER JOIN
- 두 데이터프레임의 모든 열을 기준으로 데이터를 합친다.
- 공통된 열이 없는 경우, NaN으로 채워진다.
pd.merge(df1, df2, on='column_name', how='outer')
LEFT JOIN
- 왼쪽 데이터프레임의 모든 열을 기준으로 데이터를 합친다.
- 오른쪽 데이터프레임의 공통된 열이 없는 경우, NaN으로 채워진다.
pd.merge(df1, df2, on='column_name', how='left')pd.merge(df1, df2, left_on='column_name1', right_on='column_name2', how='left')
RIGHT JOIN
- 오른쪽 데이터프레임의 모든 열을 기준으로 데이터를 합친다.
- 왼쪽 데이터프레임의 공통된 열이 없는 경우, NaN으로 채워진다.
pd.merge(df1, df2, on='column_name', how='right')
Sort
- 데이터프레임을 정렬하는 함수
df.sort_values(): 데이터프레임을 정렬하는 함수df.sort_values(by='column_name'): column_name을 기준으로 오름차순 정렬df.sort_values(by='column_name', ascending=False): column_name을 기준으로 내림차순 정렬df.sort_index(): 인덱스를 기준으로 오름차순 정렬df.sort_index(ascending=False): 인덱스를 기준으로 내림차순 정렬df.sort_values(by=['column_name1', 'column_name2']): column_name1, column_name2를 기준으로 오름차순 정렬
import pandas as pd
data = {
'name': ['A', 'B', 'C', 'D', 'E'],
'score': [100, 90, 80, 70, 60],
'grade': ['A', 'B', 'C', 'D', 'F']
}
df = pd.DataFrame(data)
# 데이터프레임을 정렬하는 함수
print(df.sort_values(by='score')) # score를 기준으로 오름차순 정렬
print(df.sort_values(by='score', ascending=False)) # score를 기준으로 내림차순 정렬
print(df.sort_index()) # 인덱스를 기준으로 오름차순 정렬
print(df.sort_index(ascending=False)) # 인덱스를 기준으로 내림차순 정렬
print(df.sort_values(by=['score', 'grade'])) # score, grade를 기준으로 오름차순 정렬Filter
- 데이터프레임을 필터링하는 함수
df['column_name'] > 10: column_name의 값이 10보다 큰 데이터를 필터링하고 True, False로 반환df[df['column_name'] > 10]: column_name의 값이 10보다 큰 데이터를 필터링해서 반환
import pandas as pd
data = {
'name': ['A', 'B', 'C', 'D', 'E'],
'score': [100, 90, 80, 70, 60],
'grade': ['A', 'B', 'C', 'D', 'F']
}
df = pd.DataFrame(data)
# 데이터프레임을 필터링하는 함수
print(df['score'] > 70) # score의 값이 70보다 큰 데이터를 필터링하고 True, False로 반환
# True True True False False
print(df[df['score'] > 70]) # score의 값이 70보다 큰 데이터를 필터링해서 반환
# name score grade
# 0 A 100 A
# 1 B 90 B
# 2 C 80 CGroupby
- 데이터프레임을 그룹핑하는 함수
df.groupby('column_name'): column_name을 기준으로 데이터를 그룹핑df.groupby("묶음의 기준이 되는 컬럼명")["적용받는 컬럼"].적용받는 연산()

import pandas as pd
people = {
'name': ['A', 'B', 'C', 'D', 'E'],
'age': [20, 30, 25, 35, 40],
'city': ['Seoul', 'Busan', 'Seoul', 'Busan', 'Seoul']
}
df = pd.DataFrame(people)
# 데이터프레임을 그룹핑하는 함수
print(df.groupby('city').mean()) # city를 기준으로 데이터를 그룹핑
# age
# city
# Busan 32.5
# Seoul 28.3
print(df.groupby('city')[['age']].mean()) # city를 기준으로 age를 그룹핑, age의 평균을 구함
# age
# city
# Busan 32.5
# Seoul 28.3Export Data (File I/O)
to Excel
- 데이터프레임을 엑셀 파일로 저장하는 함수
pd.to_excel(): 데이터프레임을 엑셀 파일로 저장하는 함수pd.to_excel('file_name.xlsx')pd.to_excel('file_name.xlsx', index=False)pd.to_excel('file_name.xlsx', sheet_name='sheet_name')
pd.read_excel(): 엑셀 파일을 데이터프레임으로 불러오는 함수pd.read_excel('file_name.xlsx')
import pandas as pd
data = {
'name': ['A', 'B', 'C', 'D', 'E'],
'score': [100, 90, 80, 70, 60],
'grade': ['A', 'B', 'C', 'D', 'F']
}
df = pd.DataFrame(data)
# 데이터프레임을 엑셀 파일로 저장하는 함수
df.to_excel('file_name.xlsx', sheet_name='sheet_name')
# 엑셀 파일을 데이터프레임으로 불러오는 함수
df = pd.read_excel('file_name.xlsx')to CSV
- 데이터프레임을 CSV 파일로 저장하는 함수
pd.to_csv(): 데이터프레임을 CSV 파일로 저장하는 함수pd.to_csv('file_name.csv')pd.to_csv('file_name.csv', index=False)
Excel 과 비교했을 때, CSV 파일은 데이터를 저장할 때 더 많은 메모리를 사용한다. (데이터를 압축하지 않기 때문)
하지만 CSV 파일은 엑셀 파일보다 더 많은 데이터를 저장할 수 있다. (데이터를 압축하지 않기 때문)
to SQL
DB에 데이터를 저장하는 함수
pd.to_sql(): 데이터프레임을 SQL 데이터베이스에 저장하는 함수pd.to_sql('table_name', 'connection')
import pandas as pd
data = {
'name': ['A', 'B', 'C', 'D', 'E'],
'score': [100, 90, 80, 70, 60],
'grade': ['A', 'B', 'C', 'D', 'F']
}
df = pd.DataFrame(data)
# 데이터프레임을 SQL 데이터베이스에 저장하는 함수
df.to_sql('table_name', 'connection')- connection은 SQL 데이터베이스에 연결하는 객체
sqlite3.connect('database.db')
- 데이터베이스에 저장할 때, 데이터프레임의 인덱스는 자동으로 인덱스로 저장된다.
pd.to_sql('table_name', 'connection', index=False)
- 데이터베이스에 저장할 때, 데이터프레임의 인덱스를 컬럼으로 저장할 수 있다.
pd.to_sql('table_name', 'connection', index=True, index_label='index')
Summarize Data
- 데이터프레임의 요약 통계량을 확인하는 함수
df.info(): 데이터프레임의 요약 정보를 확인하는 함수df.describe(): 데이터프레임의 요약 통계량을 확인하는 함수
import pandas as pd
data = {
'name': ['A', 'B', 'C', 'D', 'E'],
'score': [100, 90, 80, 70, 60],
'grade': ['A', 'B', 'C', 'D', 'F']
}
df = pd.DataFrame(data)
# 데이터프레임의 요약 정보를 확인하는 함수
print(df.info())
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 5 entries, 0 to 4
# Data columns (total 3 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 name 5 non-null object
# 1 score 5 non-null int64
# 2 grade 5 non-null object
# dtypes: int64(1), object(2)
# memory usage: 248.0+ bytes
# None
# 데이터프레임의 요약 통계량을 확인하는 함수
print(df.describe())
# score
# count 5.000000
# mean 80.000000
# std 15.811388
# min 60.000000
# 25% 70.000000
# 50% 80.000000
# 75% 90.000000
# max 100.000000Melt
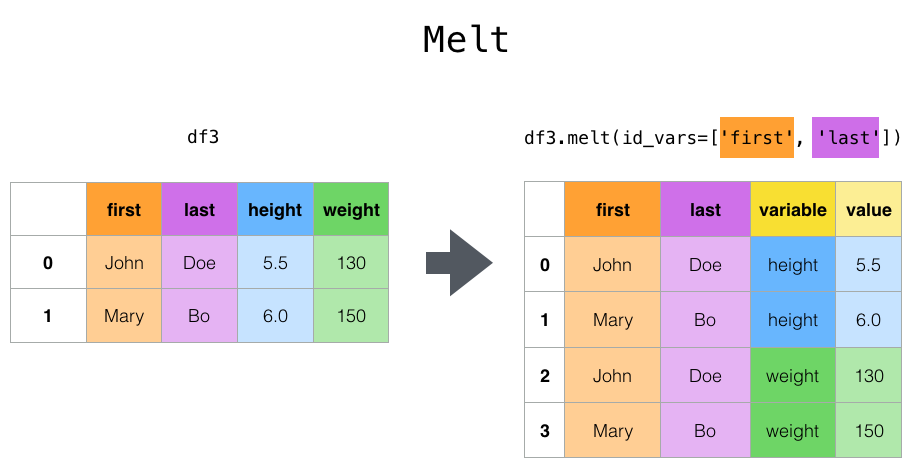
- 데이터프레임을 재구조화하는 함수
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None, ignore_index=True)
import pandas as pd
data = {
'name': ['A', 'B', 'C', 'D', 'E'],
'math': [100, 90, 80, 70, 60],
'english': [90, 80, 70, 60, 50],
'science': [80, 70, 60, 50, 40]
}
df = pd.DataFrame(data)
# 데이터프레임을 재구조화하는 함수
print(pd.melt(df, id_vars=['name'], value_vars=['math', 'english', 'science'], var_name='subject', value_name='score'))
# name subject score
# 0 A math 100
# 1 B math 90
# 2 C math 80
# 3 D math 70
# 4 E math 60
# 5 A english 90
# 6 B english 80
# 7 C english 70
# 8 D english 60
# 9 E english 50
# 10 A science 80
# ...id_vars: 고정할 열 이름value_vars: 재구조화할 열 이름var_name: 재구조화한 열 이름value_name: 재구조화한 값 이름col_level: 멀티 인덱스를 사용할 때, 열 이름의 레벨ignore_index: 인덱스를 무시할지 여부
Pivot Table
- 데이터프레임을 피벗 테이블로 변환하는 함수
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False)
피벗 테이블: 데이터프레임을 재구조화하여 요약된 정보를 보여주는 테이블
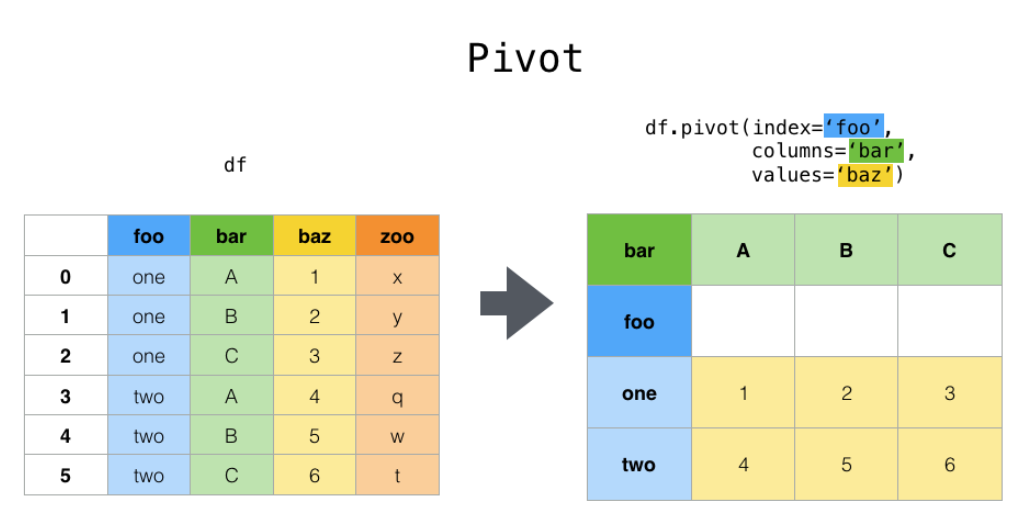
import pandas as pd
data = {
'name': ['A', 'B', 'C', 'D', 'E'],
'math': [100, 90, 80, 70, 60],
'english': [90, 80, 70, 60, 50],
'science': [80, 70, 60, 50, 40]
}
df = pd.DataFrame(data)
# 데이터프레임을 피벗 테이블로 변환하는 함수
print(pd.pivot_table(df, values=['math', 'english', 'science'], index='name', aggfunc='mean'))
# english math science
# name
# A 90 100 80
# B 80 90 70
# C 70 80 60
# D 60 70 50
# E 50 60 40values: 피벗 테이블로 변환할 열 이름index: 행 인덱스로 사용할 열 이름columns: 열 인덱스로 사용할 열 이름aggfunc: 집계 함수fill_value: NaN을 채울 값margins: 행과 열의 합계를 보여줄지 여부dropna: NaN을 제거할지 여부margins_name: 합계의 이름observed: 카테고리가 없는 경우, NaN을 채울지 여부col_level: 멀티 인덱스를 사용할 때, 열 이름의 레벨ignore_index: 인덱스를 무시할지 여부sort: 행 인덱스를 정렬할지 여부
'[Project_하다] > [Project_공부]' 카테고리의 다른 글
| [우리FISA] Data Visualization (0) | 2024.07.19 |
|---|---|
| [우리FISA] EDA(Exploratory Data Analysis) (0) | 2024.07.19 |
| [@mohsin.shaikh324] Matplotlib vs. Seaborn vs. Plotly (0) | 2024.07.19 |
| [우리FISA] NumPy (0) | 2024.07.17 |
| [우리FISA] Python Class (0) | 2024.07.16 |
| [우리FISA] OOP (0) | 2024.07.15 |
| [우리FISA] Standard Input/Output, stdio (0) | 2024.07.15 |


