
Tags
- 우리에프아이에스
- 축복이
- 17-55
- 해리포터
- 도쿄
- 대만
- 전주
- 전시
- 시청
- ai_엔지니어링
- 군산
- 대만여행
- 사진
- SQL
- 건담
- 여행
- 오사카
- Python
- 수요미식회
- k-디지털트레이닝
- 카페
- 축복렌즈
- 맛집
- 글로벌소프트웨어캠퍼스
- CS231n
- 650d
- fdr-x3000
- 우리fis아카데미
- 우리fisa
- 제주도
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Today
- Total
Recent Posts
300x250
브렌쏭의 Veritas_Garage
[우리FISA] Data Visualization 본문
데이터 시각화의 중요성
데이터 시각화를 통해 데이터 분석 결과를 쉽게 이해할 수 있고, 데이터 간의 관계를 파악할 수 있다.
데이터 종류별 시각화
- 데이터 시각화의 가장 중요한 효과는 자료로부터 습득하는 시간 절감이다.
-
- 여러 종류의 데이터를 통합하여 모든 사람이 이해할 수 있는 방식으로
- 핵심 메트릭(측정 체계(metric))과 인사이트를 표시하는 화면을 의미한다.
- 점수, 수치로 측정할 수 있는 어떤 값들 (속도, 버즈량, 정확도) 대표값대시보드 : 다양한 데이터를 동시에 비교할 수 있게 해 주는 여러 뷰의 모음.
-
데이터 대시보드란 무엇인가요 | Microsoft Power BI
비즈니스 인텔리전스 항목 - 동향 및 솔루션 | Microsoft Power BI
데이터 기반의 조직 문화 조성에 도움이 되는 데이터 및 분석을 설명한 비즈니스 인텔리전스(BI) 문서를 살펴보세요.
powerbi.microsoft.com
데이터의 종류에 따른 분류
질적 변수(qualitative variable), 범주형(categorical) 변수
- 둘 다 ‘비율’이 의미를 가진다.
- 조사 대상을 특성에 따라 범주로 구분하여 측정된 변수로 범주형 변수(categorical data)라고도 함.
- 질적 변수에 대해 덧셈 등 수학적 연산결과는 아무런 의미가 없기 때문에 연산의 개념을 적용시킬 수 없다.
- 질적 변수가 분석 대상일 때는 각 범주에 속한 개수나 퍼센트 등을 다룬다.
양적 변수(quantitative variable)
시간 시각화 (연속형 변수)

- 시계열 데이터의 가장 특징적인 요소는 트렌드(Trend), 즉 경향성으로 장기간에 걸쳐 진행되는 변화 또는 트렌드를 추적하는 데 주로 사용된다.
- 시간 데이터는 분절형(이산형)과 연속형으로 나눌 수 있다.
- 분절형은 데이터의 특정 시점 또는 시간으로 구간을 나눈 것.
- 시간별 미세먼지 변화량 vs 10분마다 측정한 미세먼지변화량
분포 시각화
원그래프

- 원그래프는 크기가 비슷하지만 서로 인접해 있지 않은 파이 조각들을 비교하기가 어렵다.
- 그러므로 최대한 구성요소(3-5개 미만의 데이터를 시각화하는 것이 좋다) 를 제한하고, 내용을 설명하기 위한 텍스트와 퍼센티지를 포함시키는 것이 좋다.
트리맵

- 영역 기반의 시각화로 각 사각형의 크기가 수치를 나타낸다. 한 사각형을 포함하고 있는 바깥 영역은 그 사각형이 포함된 대분류, 내부 사각형은 내부적인 세부 분류를 의미한다.
- 단순 분류별 분포 시각화 뿐 아니라 위계 구조가 있는 데이터나 트리 구조의 데이터를 표시할 때 활용된다.
누적 연속 그래프
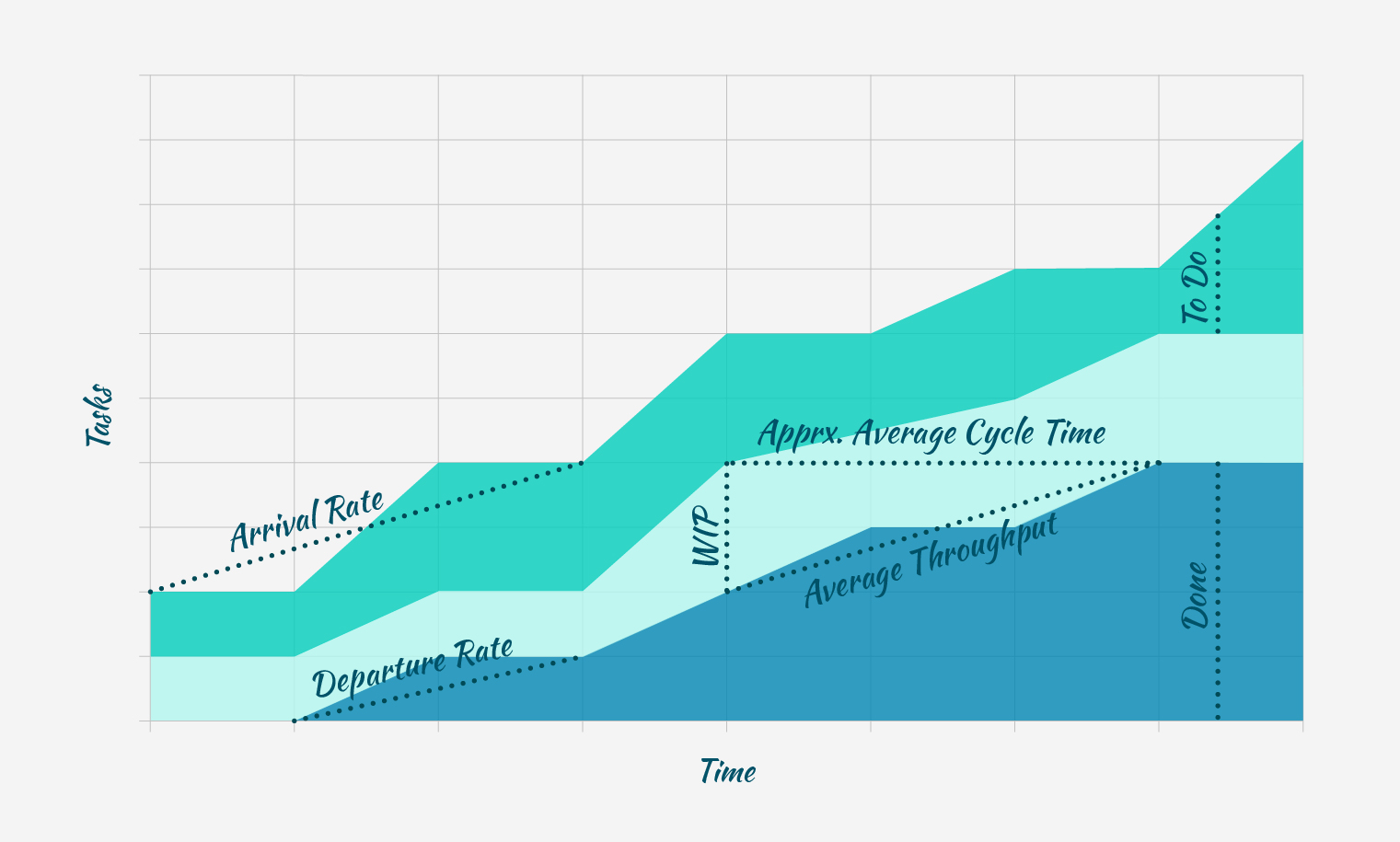
- 몇 개의 시계열 그래프를 차곡차곡 쌓아올려 그려 빈 공간을 채워간다.
- 가로축은 시간, 세로축은 데이터값을 나타낸다.
- 누적 영역그래프에서 한 시점의 세로 단면을 가져오면 그 시점의 분포를 볼 수 있다.
관계 시각화
- 상관관계를 알면 한 수치의 변화를 통해 다른 수치의 변화가 예측 가능하다.
산점도, 스캐터 플롯
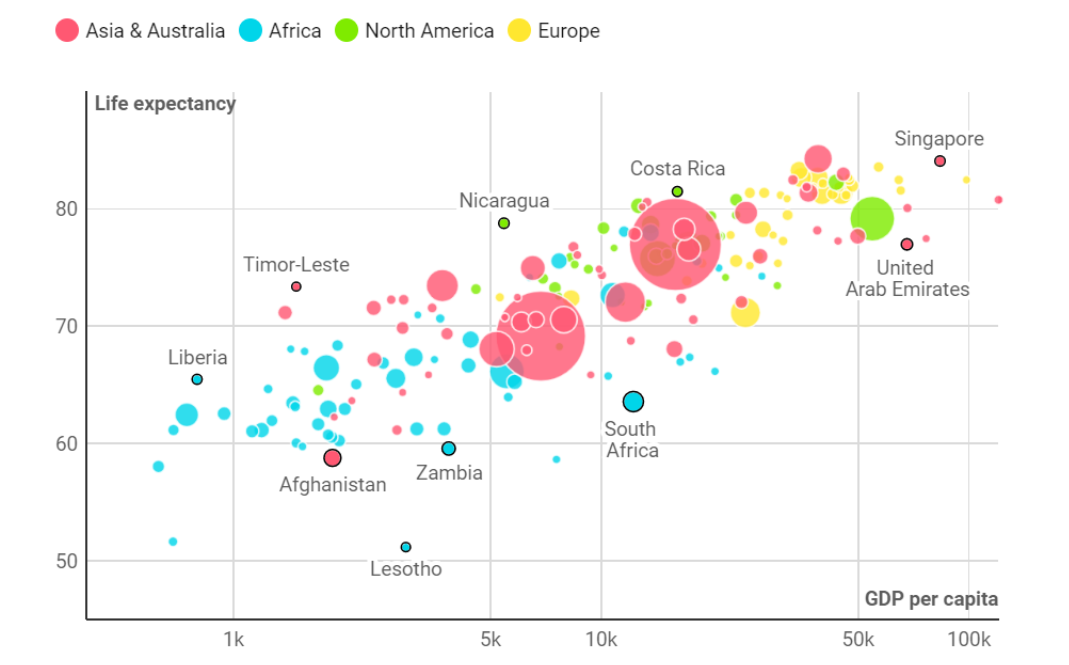
- 두 데이터 항목의 공통변이를 나타내는 2차원 도표
- 양의 상관관계 / 음의 상관관계 / 관계가 없다
- 상관관계가 높아보이는 특성들만 선택하면 추론의 결과가 낮아지는 경우가 많다
- 빅데이터 분야에서는 0.15 정도만 넘어도 상관관계가 있다고 판단한다.
- 포인트가 많을 때 유용하나, 포인트 수가 적은 경우에는 오히려 막대그래프나 일반 표가 효과적일 수 있다.
버블 차트
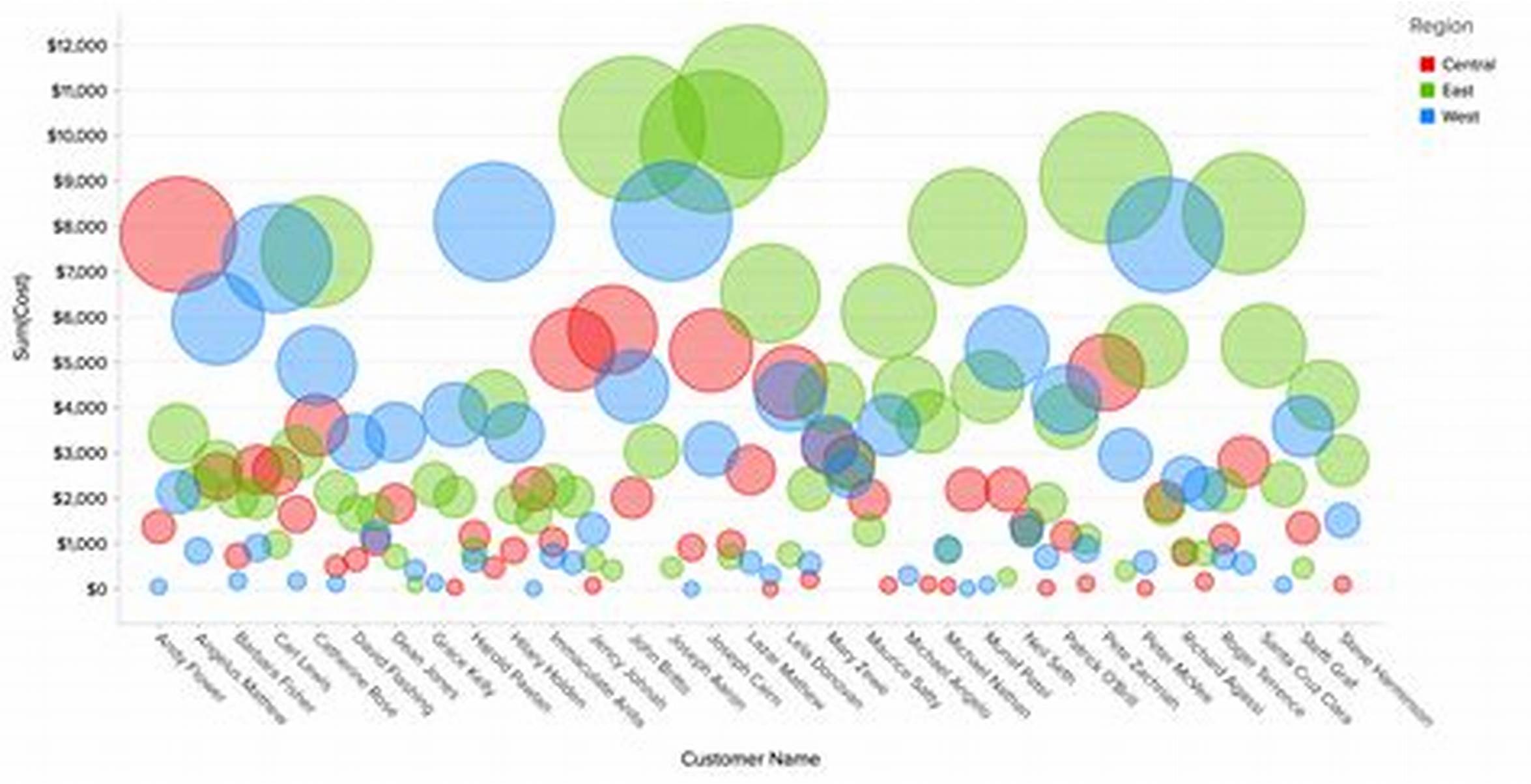
- 산점도에 각 요소별 크기(비중)를 더함으로써 세가지 요소의 상관관계를 표현할 수 있는 방법
- 가로축 변수, 세로축 변수, 버블의 크기
- 값들이 몇자릿수씩 차이가 나는 데이터 셋이 유용
- 원의 면적이 아니라 지름을 가지고 판단하는 경향이 있다.
히스토그램
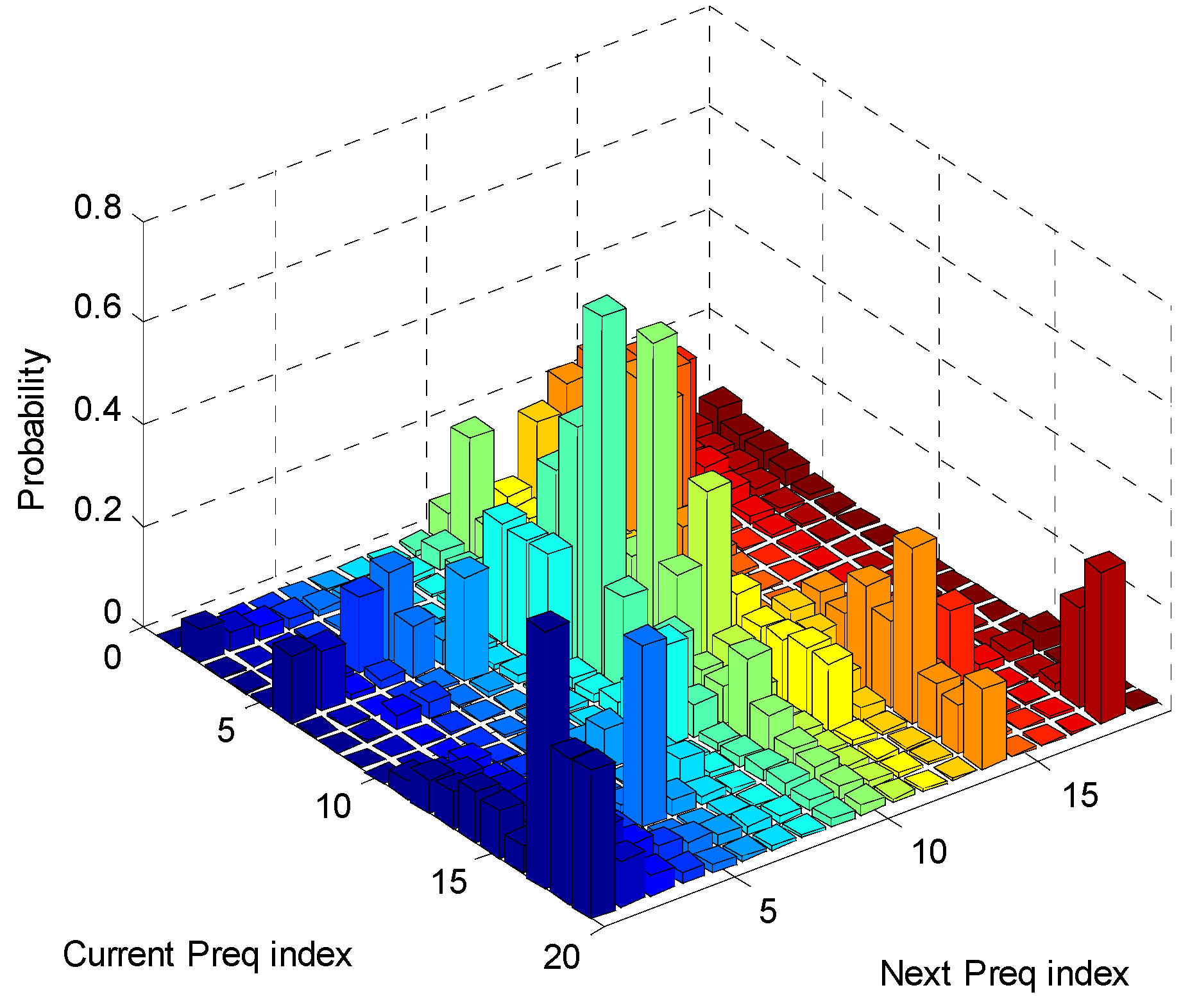
- 높이는 빈도를 의미, 폭은 대개 의미가 없다
- 가로, 세로축은 연속적이다
비교 시각화
히트맵
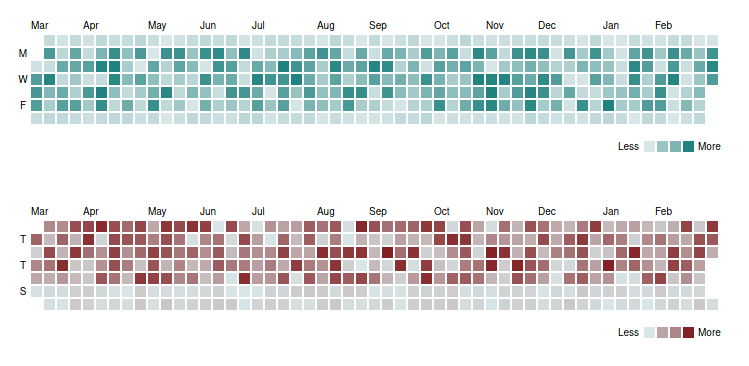
- 가장 많이 유용하게 쓰이는 그래프 중 하나
- 가로는 변수, 세로는 단위
- 한 칸의 색상으로 데이터값을 표현한다
- 더 밝은 색이 더 많은 수, 어두운 색이 작은 수를 표시하도록
체르노프 페이스
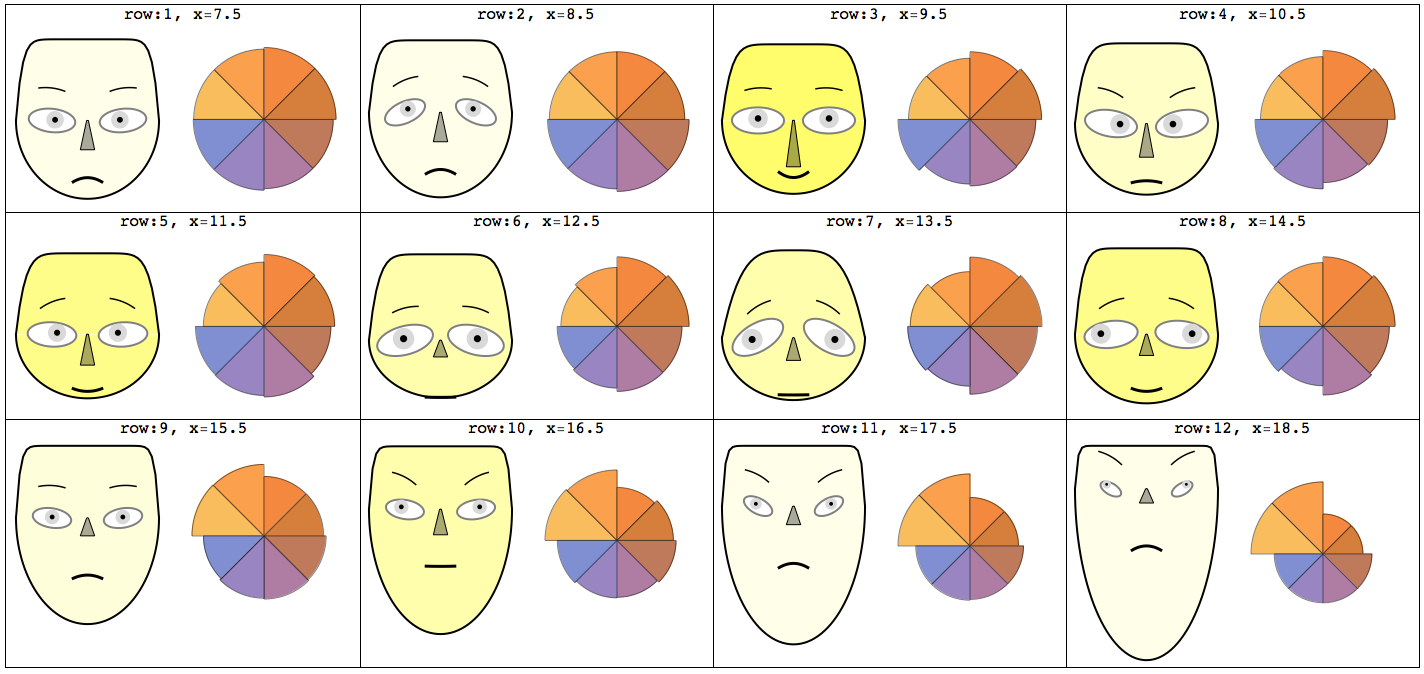
- 데이터를 사람의 얼굴 이미지로 표현하는 방법
- 얼굴의 각 부위를 변수로 대체한다
다차원척도법
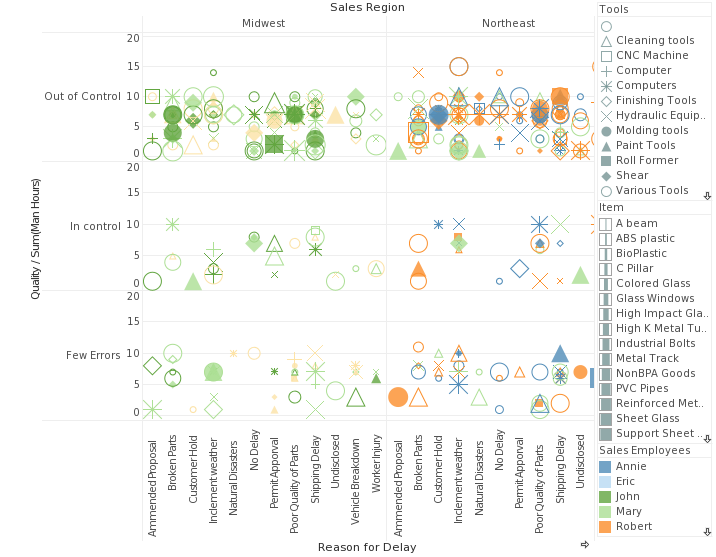
- 데이터셋 상의 개별 데이터 간의 유사도를 바탕으로 시각화하는 방법
- 유사성이 작은 대상끼리는 멀리, 유사성이 큰 대상끼리는 가까이 위치시킨다
- 군집분석, 제품 포지셔닝과 제품 디자인 등에 주로 사용되고 있다
공간시각화
Geocoding
- 좌표계를 행정구역으로 묶어서 변환해주거나 그 반대로 변환해 주는 것
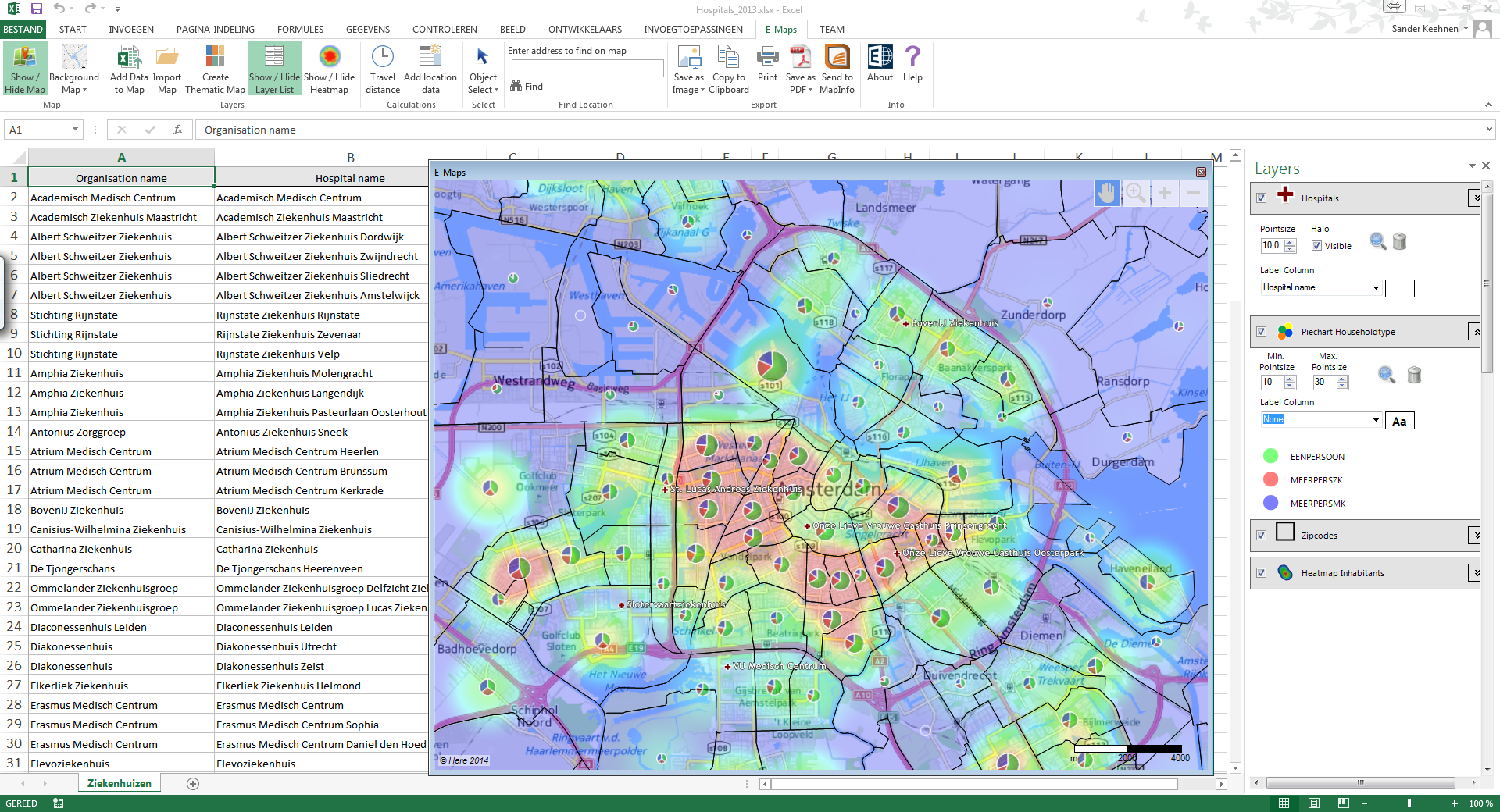
그 와중에 엑셀 미쳤네
'[Project_하다] > [Project_공부]' 카테고리의 다른 글
| [Streamlit] Python을 이용한 간단한 배포 (0) | 2024.07.23 |
|---|---|
| [Data Visualization] Libraries (0) | 2024.07.22 |
| [우리FISA] 2주차 회고 Python Libraries (1) | 2024.07.19 |
| [우리FISA] EDA(Exploratory Data Analysis) (0) | 2024.07.19 |
| [@mohsin.shaikh324] Matplotlib vs. Seaborn vs. Plotly (0) | 2024.07.19 |
| [우리FISA] Pandas method and functions (0) | 2024.07.18 |
| [우리FISA] NumPy (0) | 2024.07.17 |
'[Project_하다]/[Project_공부]' Related Articles
more




Comments